4.4.3. Sistemas Operativos: CPU y Procesos


Docly Child
En este punto se va mostrar formas para obtener información de la CPU y trazados de llamadas a sistema de aplicaciones para completar la información del punto anterior. Además se ampliará la información sobre procesos, memoria y almacenamiento (en el siguiente punto). Las prácticas se van a realizar pensando en los Sistemas Operativos (SO a partir de ahora) más habituales: Windows y Linux. En concreto un Windows 10 y la distribución Linux-Debian de Kali Linux que se ha empleado de forma regular en esta publicación.
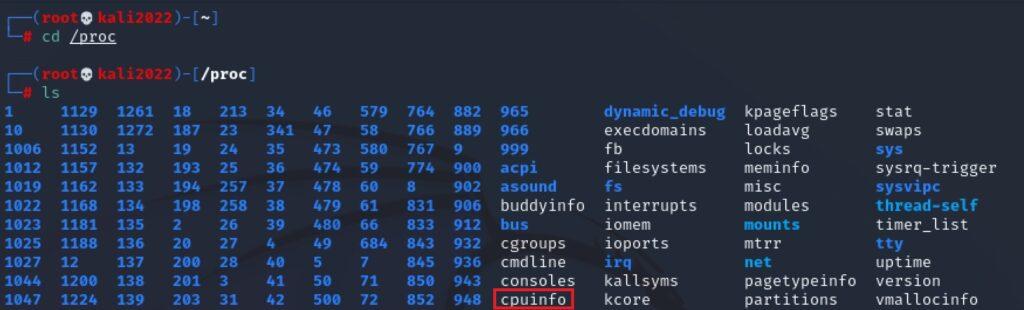
Muchas de las distribuciones del SO Linux tienen lo que se llama el sistema de archivos proc filesystem o procfs. procfs es un sistema de archivos que se halla en el directorio /proc y que genera información del sistema de forma dinámica incluyendo datos de la CPU y los procesos entre otros. Se puede acceder y listar este sistema de archivos con los siguientes comandos desde la terminal:
cd /proc
ls
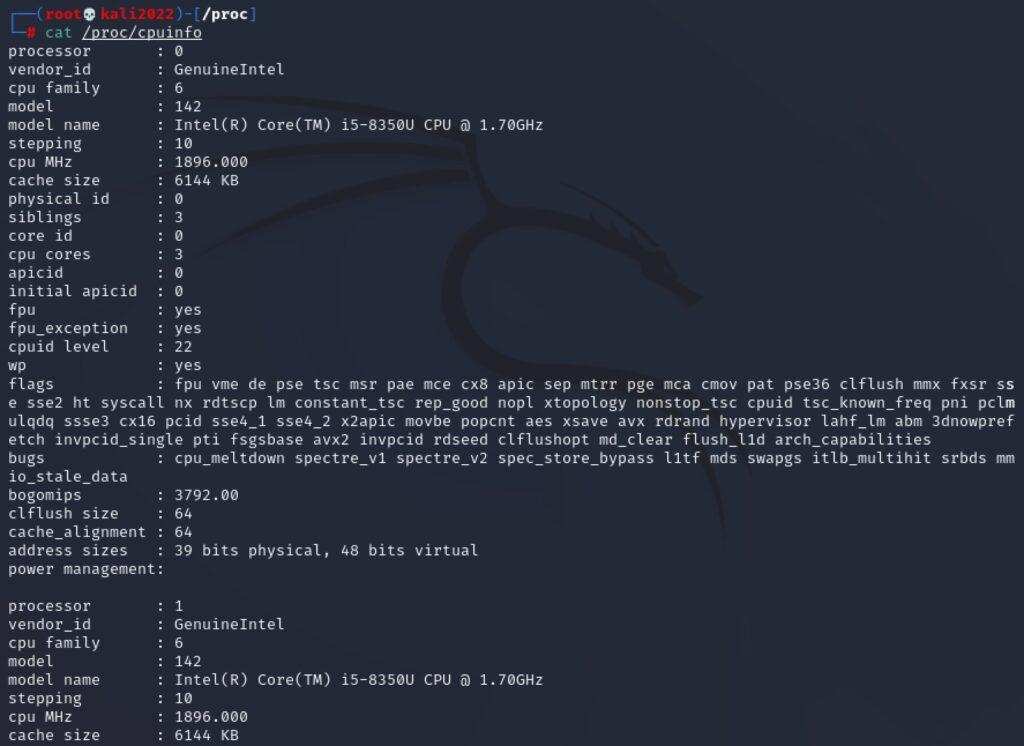
procfs está implementado en el núcleo del Sistema Operativo y en realidad no son archivos reales ni consumen espacio de almacenamiento. Sin esta utilidad sería muy difícil acceder a la información del sistema. Uno de estos archivos es cpuinfo, que proporciona información del procesador (CPU). Para acceder a la información que proporciona este fichero y otros se va a utilizar el comando cat:
cat /proc/<archivo_procfs>
Como puede observarse procfs incluye una amplia gama de archivos para obtener información de los temas tratados en puntos anteriores como es interrupts, devices, meminfo, versión…
Windows no dispone de un sistema de archivos como procfs en Linux para obtener información del sistema. Desde el escritorio gráfico y con el surtido de aplicaciones que proporciona al usuario la interfaz de Windows es posible obtener información acerca del sistema (Propiedades del sistema, Ver información del sistema…). No obstante la información proporcionada así suele ser escasa y es preferible optar por otros medios.
Una de las opciones para acceder a la información del sistema en Windows es emplear las herramientas de Sysinternals. Sysinternals es un conjunto de herramientas desarrolladas por Mark Russinovich. Si bien al principio Sysinternals era una empresa aparte de Windows, finalmente la empresa del SO la absorbió y puede encontrarse la información en la siguiente página: https://learn.microsoft.com/en-us/sysinternals/
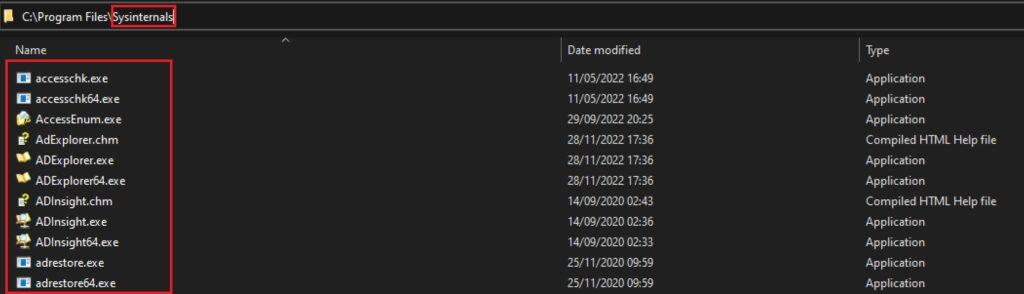
Systinternals en realidad está formado por varios archivos ejecutables, proporcionando cada uno de ellos una determinada información. Se puede descargar en: https://learn.microsoft.com/en-us/sysinternals/downloads/
Una vez descargado el fichero principal comprimido, se recomienda crear un nuevo directorio C:\Program Files\Sysinternals y descomprimir y ubicar en este directorio todos los ficheros para acceder posteriormente con la consola de línea de comandos CMD:
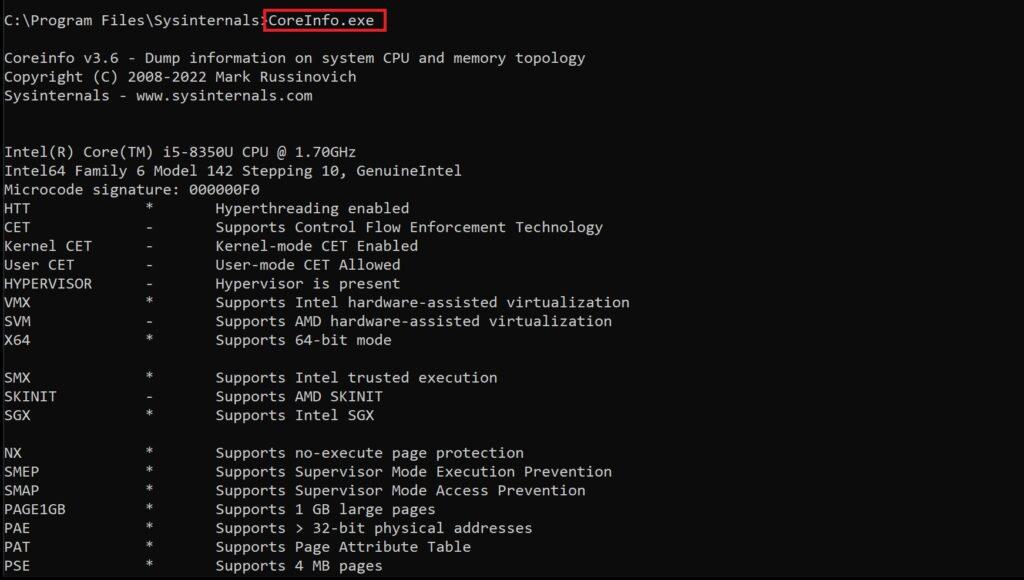
Existen utilitarios (.EXE) para obtener información de usuarios, de red, procesos, etc. Para obtener información sobre la CPU se puede emplear coreinfo.exe o CoreInfo.exe. Este proporciona información acerca de si el procesador y el SO tienen diferentes rasgos como tipos de instrucciones especiales que soporta, si tiene PAE (extensión de direcciones físicas), equivalencia entre procesadores lógicos y físicos, caché asignada al procesador, etc.
cd C:\Program Files\Sysinternals
CoreInfo.exe
A continuación se va a mostrar dos herramientas para seguir la traza de las system call de un proceso y mostrar por pantalla como se interceptan y se registran. Estas herramientas aparte de proporcionar información también resultan útiles a los desarrolladores de software para depurar y analizar el funcionamiento interno de un programa.
El software para trazar llamadas al sistema para Linux más sencillo de utilizar es el que nos proporciona la herramienta strace (System Call Trace). Esta se utiliza a través de la consola de línea de comandos y en caso de no estar instalada se puede hacer con el gestor de paquetes apt con el siguiente comando:
sudo apt update && sudo apt strace
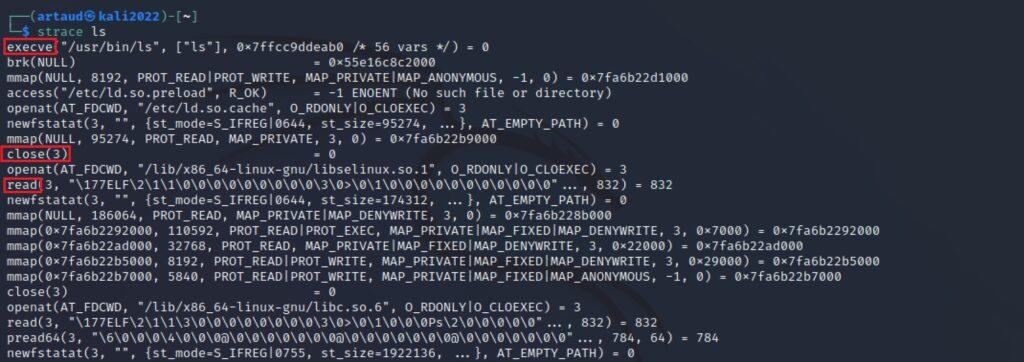
Para realizar la práctica se puede emplear cualquier comando básico que genera un proceso en sí como sería listar directorios (ls), leer un fichero con cat, etc. Cada línea mostrada contiene el nombre de la llamada al sistema seguida de sus argumentos y valores retornados.
strace < ls | cat [archivo] | pwd | … >
Puede apreciarse en el ejemplo que se están empleando algunas de las llamadas a sistema que se han mencionado anteriormente: execve, close, read…
Para realizar una práctica similar y ver el trazado de llamadas a sistema con el SO Windows se va a emplear una herramienta de software que cuenta ya con sus años. Esta es StraceNT. Puede descargarse en el siguiente enlace: https://www.softpedia.com/get/Programming/Debuggers-Decompilers-Dissasemblers/StraceNT.shtml
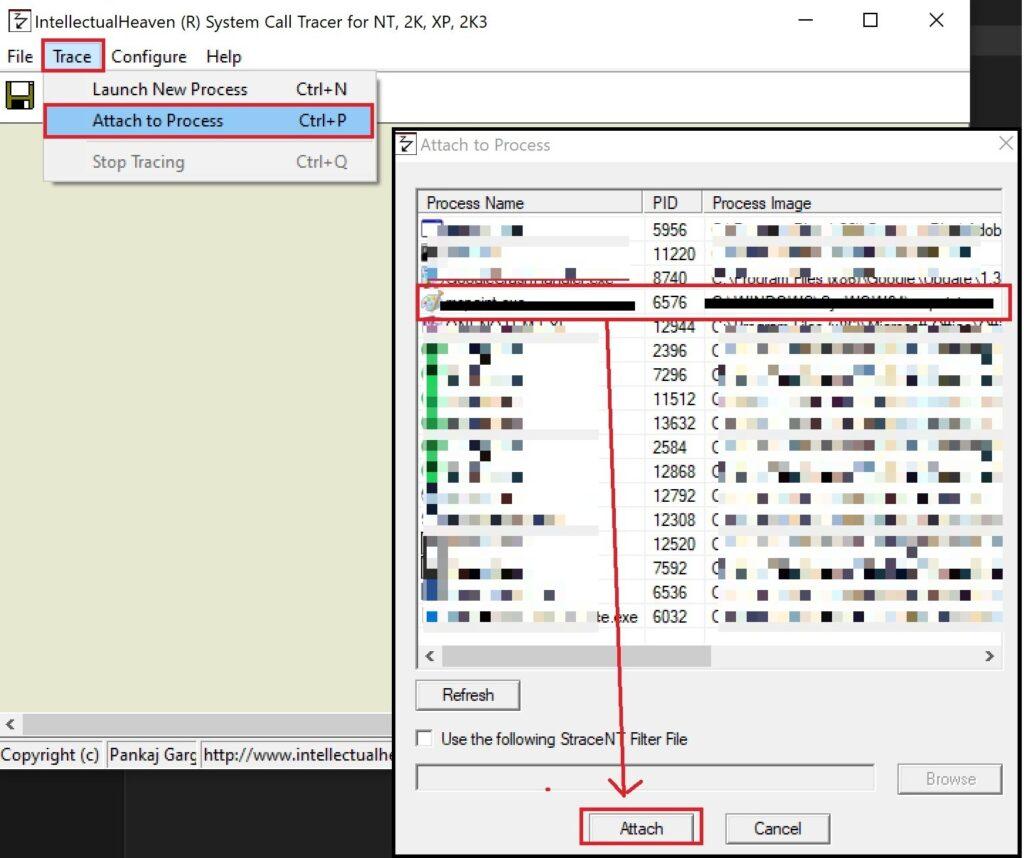
Una vez descargado se puede emplear a través de la consola de línea de comandos con el fichero stracent.exe o bien con una interfaz gráfica con el fichero straceui.exe. Para la práctica se va a emplear la solución gráfica straceui. Una vez abierta la aplicación se puede emplear diferentes filtros que no se van a explicar aquí o bien se puede seleccionar un ejecutable y ver cómo trabaja (Launch New Process). En este caso se ha capturado un proceso ya existente (Attach to Process):
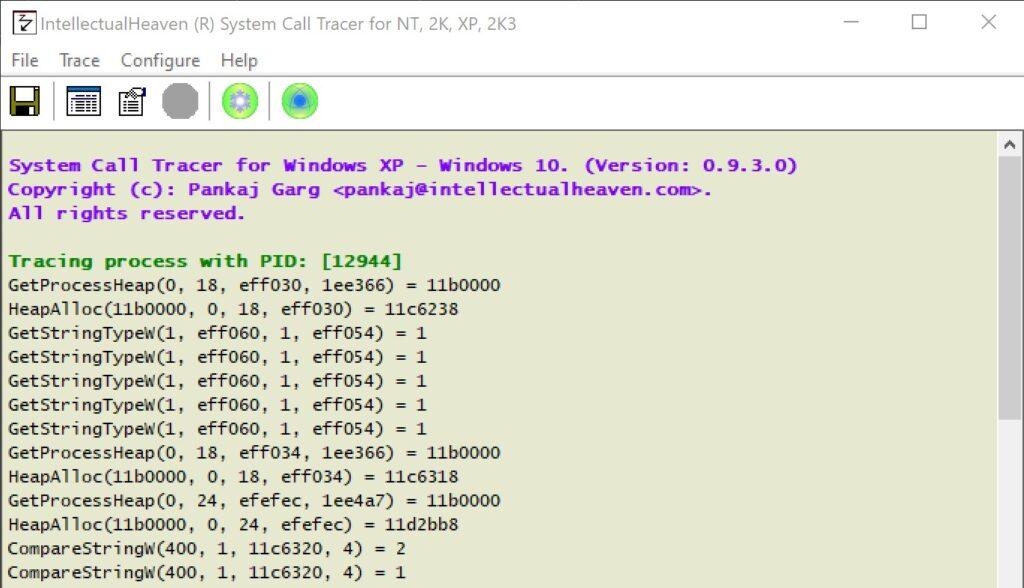
Los resultados mostraran el tipo de llamada a sistema empleado, argumentos retornados y valores retornados. Como se aprecia en la imagen, la terminología empleada por el SO Windows es diferente a la distribución de Linux:
En el punto anterior ya se ha dado una definición más o menos precisa de lo que es un proceso. En todo caso es una entidad dinámica y se refiere al conjunto de instrucciones en ejecución de un programa o la instancia de un programa que está en ejecución. El objetivo principal de este punto es realizar una práctica para crear un proceso con la llamada a sistema fork. En los siguientes puntos se analizará en detalle cómo se define un proceso en Windows y Linux y como obtener información de los procesos que se están ejecutando en cada SO. Esta información será fundamental para las operaciones de postexplotación.
A continuación se describen brevemente algunas de las características que representan a los procesos:
Otros conceptos fundamentales que convienen mencionar son el planificador (scheduler) y el activador (dispatcher). Sin entrar en detalles, ambos forman parte del código del núcleo del Sistema Operativo y como el nombre indica el objetivo del primero es seleccionar que proceso debe ejecutarse a continuación de otro mientras que el activador pone en ejecución el proceso seleccionado. Además, en el contexto de los procesos padre-hijo es habitual que los hijos pueden comunicarse con el proceso padre o con otros procesos a través de mecanismos de comunicación interprocesos, como tuberías (pipes), colas de mensajes, etc. (existen varios paradigmas de comunicación entre procesos).
En la introducción a las llamadas a sistema (systems calls) se ha explicado que existen lenguajes de programación como C que permiten instrucciones para realizar algunas de ellas directamente. Una de estas es fork(). Esta instrucción crea un nuevo proceso duplicando el existente en curso. Como ya se ha comentado arriba, una de las características de los procesos es que pueden ser hijo y/o padre. En el caso de incluir fork() en el código, el proceso padre recibe el PID (número de identificación) del proceso hijo devuelto por fork(), mientras que el proceso hijo recibe un valor de retorno de 0 indicando que es el proceso hijo (fork() == 0).
A continuación una práctica en lenguaje C para ver esto en detalle. El código sería el siguiente (incluye comentarios que se analizan abajo):
//Comentario 1
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
//Comentario 2
int main()
{
//Comentario 3
pid_t pid;
pid = fork();
//Comentario 4
switch(pid)
{
case -1:
perror("fork");
break;
case 0:
printf("Proceso %d; padre = %d\n", getpid(), getppid());
break;
default:
printf("Proceso %d; padre = %d\n", getpid(), getppid());
break;
}
return 0;
}
Para los usuarios que no sepan de lenguaje C o no tengan conocimientos de programación, estos son los comentarios:
Una vez comprendido el código, es necesario saber cómo ejecutarlo. En lenguaje C es de nivel medio-alto y para ejecutar las instrucciones del código es necesario realizar el proceso de compilación. Para ello seguir los siguientes pasos en Kali Linux o alguna versión similar de Linux:
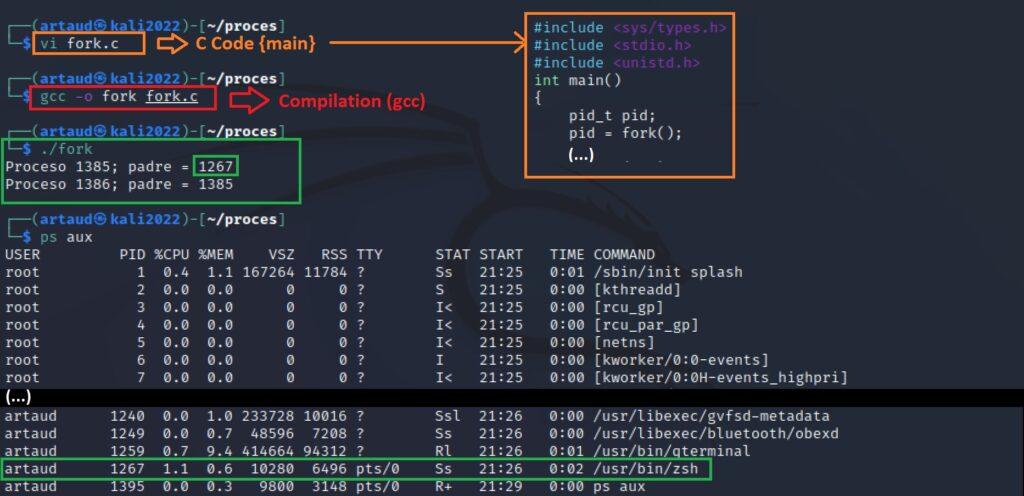
1. Copiar el código mostrado en un fichero con algún editor de texto y guardarlo (en la imagen se ha utilizado vi). Debe tener extensión .c para indicar que es un fichero con información de código en lenguaje C. No es necesario incluir los comentarios (indicados por doble barra //).
2. Para compilar utilizar el software de GCC (GNU Compiler Collection). Este software está incluido en casi todas las distribuciones de Linux y es software libre. Se compila con la siguiente instrucción en la consola de línea de comandos. En la primera opción después del parámetro -o se va a indicar el nombre que va a tener el ejecutable y en la segunda opción el fichero que contiene el código en C.
gcc –o <nombre_ejecutable> <fichero>.c
3. Para ejecutar el fichero:
./<nombre_ejecutable>
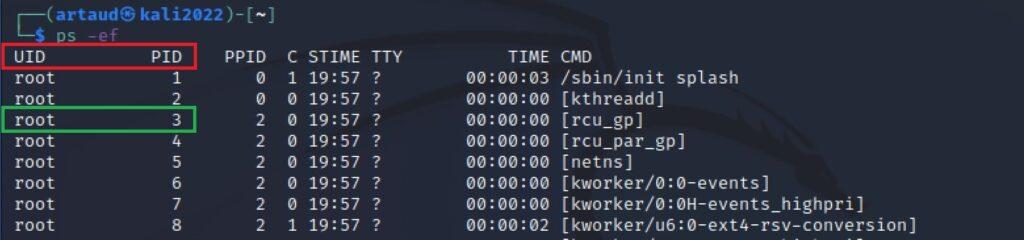
Como la función fork() realiza una copia del proceso en curso por esto se ven dos líneas de resultados. En los resultados mostrados el proceso padre tiene un ID de proceso (PID) de 1385 y su padre tiene un PID de 1267. El proceso hijo tiene un PID de 1386 y su padre tiene un PID de 1385. Esto significa que el proceso padre creó exitosamente un proceso hijo. Al visualizar los procesos que se están ejecutando también se muestra que el proceso /usr/bin/zsh se corresponde a la consola, siendo este por lo tanto el proceso padre inicial.
© Malware SA. Todos los derechos reservados.