5.1.2. Ficheros ejecutables: lenguaje objeto, compilación, debugging
5.1.2.1. Formatos de ficheros ejecutables
En la introducción se ha mencionado los archivos de código ejecutable. Resumiendo mucho, estos archivos autocontenidos permiten iniciar aplicaciones que se cargaran en la memoria principal, generando una serie de procesos (programa en ejecución) que servirán como inputs para el procesador (CPU). La creación de un fichero de este tipo no es algo trivial (a continuación se desarrollará). Denominados también binarios, en alusión a que están adaptados al lenguaje de máquina del procesador (código binario o máquina), los formatos más comunes serían:
- Executable and Linkable Format (ELF): Utilizado para SO Linux/Unix.
- Portable Executable (PE): Utilizado en SO Windows.
- Mach-O: Utilizado en SO macOS.
Este tipo de ficheros permiten ejecutarse en estos SO en concreto debido a la arquitectura y especificaciones técnicas de estos. Además, solo funcionarán para determinadas arquitecturas de CPU (32 o 64 bit) y dependiendo de la marca del procesador. Estos dos factores son determinantes a la hora de construir (compilar) el fichero ejecutable, o de lo contrario no podrá iniciarse, como se explicará a continuación. En todo caso, un fichero ejecutables es como una caja negra: cuando se inicia permite acceder a las funcionalidades de un programa o aplicación, con o sin la interacción del usuario, pero no se puede saber nada de cómo se ha construido en su origen. Solo mediante técnicas de ingeniería inversa y con las herramientas adecuadas, es posible determinar el funcionamiento y características internas del fichero, permitiendo hallar vulnerabilidades.

5.1.2.2. El formato ejecutable PE (.exe): regiones y mapa de memoria
Un fichero ejecutable no es una simple serie de unos y ceros (código máquina) que se cargan en la memoria y son procesados por la CPU, sino que este tiene una estructura y formato. Si se abre un fichero ejecutable con el bloc de notas, el sistema interpreta el contenido como texto en formato ASCII o Unicode, resultando ilegible, a excepción de la sección de manifiesto. Esta sección proporciona información de metadatos sobre el tipo de aplicación, permisos y configuración específica de Windows. Por ejemplo, para la calculadora de Windows se muestra la siguiente información:
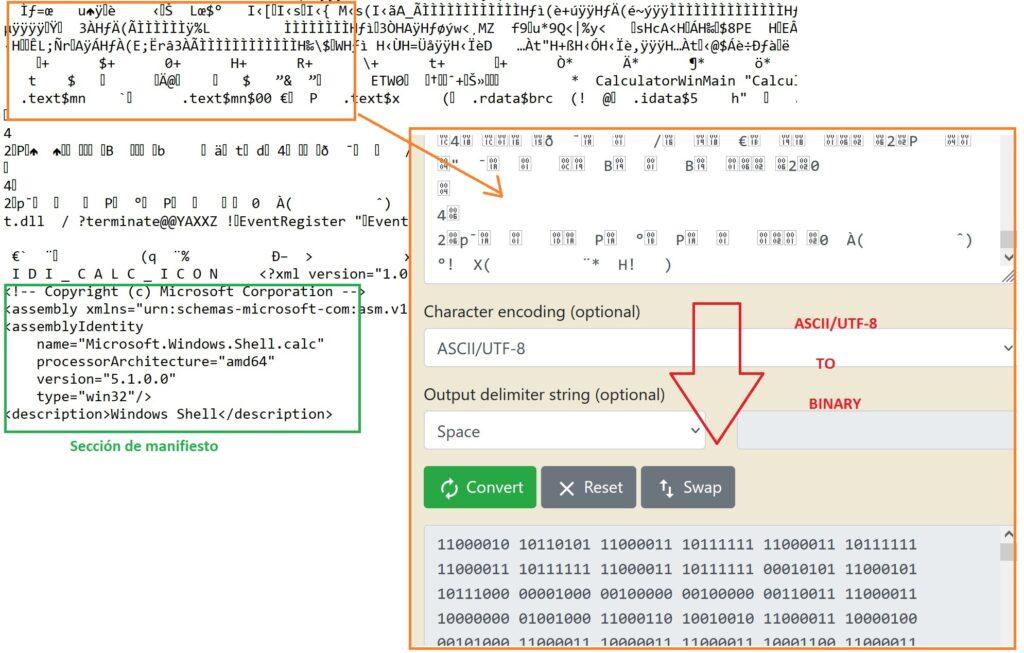
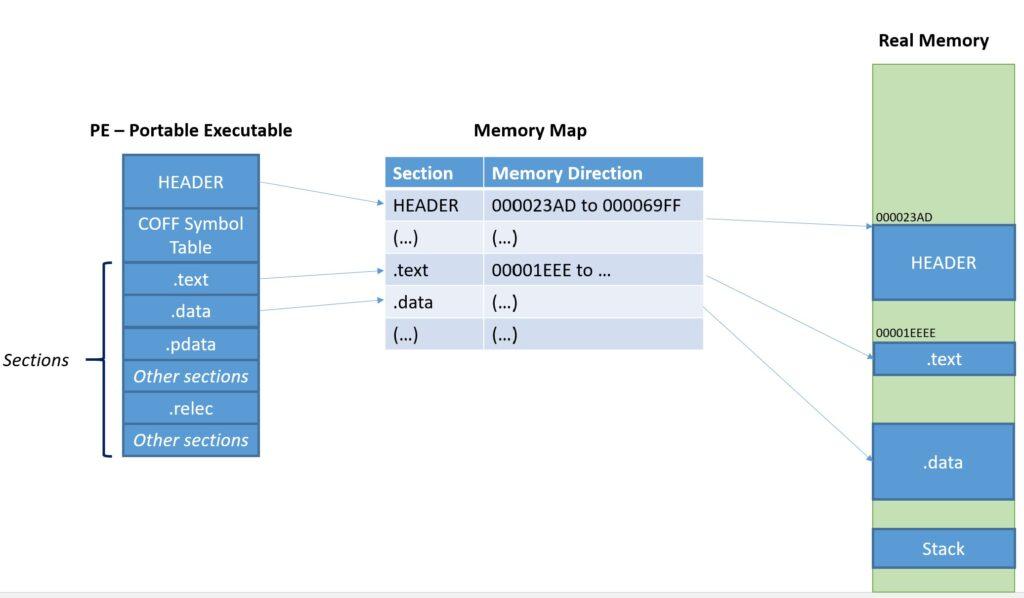
En realidad, un fichero ejecutable consta de diferentes regiones o secciones. Se define como una estructura de datos que encapsula información necesaria para el cargador de sistema operativo, que debe gestionar el código ejecutable. Mediante las operaciones de administración de memoria habituales como son la memoria virtual, paginación y segmentación, estas regiones se van cargando en la memoria como procesos, generando un mapa de memoria del proceso. Los ejecutables PE suelen contener al menos estas partes (entre paréntesis, nombre que recibiría en PE), siendo similares en algunos aspectos con otros formatos:
- Cabeceras (HEADERS): Información de control que permite interpretar el contenido del ejecutable.
- Tablas de símbolos (COFF): Los símbolos son nombres asociados a direcciones de memoria, como nombres de funciones, variables globales, y otros elementos del programa. Proporciona una forma de asociar nombres significativos a direcciones de memoria.
- Código (.text): Contiene el código del programa.
- Variables globales (.data): Son datos utilizados por el programa durante su ejecución. Incluye constantes y datos estáticos.
- Funciones y manejadores de excepción (.pdata): Una excepción es un evento anormal o inesperado que ocurre durante la ejecución de un programa y que interrumpe el flujo normal de ejecución.
- Información de reajuste de la memoria (.reloc): Esta sección contiene información de reubicación que se utiliza durante el proceso de carga del programa en memoria. Cuando un programa es cargado en una dirección de memoria específica, algunas direcciones de memoria dentro del programa pueden necesitar ser ajustadas.
El ejecutable también prevé el uso de memoria para determinadas funciones como serían la pila del proceso (stack). La pila del proceso es una región de escritura/lectura que da soporte para almacenar los registros de activación de las llamadas a las funciones dentro del programa. Basándose en estas descripciones, el siguiente cuadro esquematiza la relación entre las regiones del ejecutable y el mapa de memoria del proceso asociado:
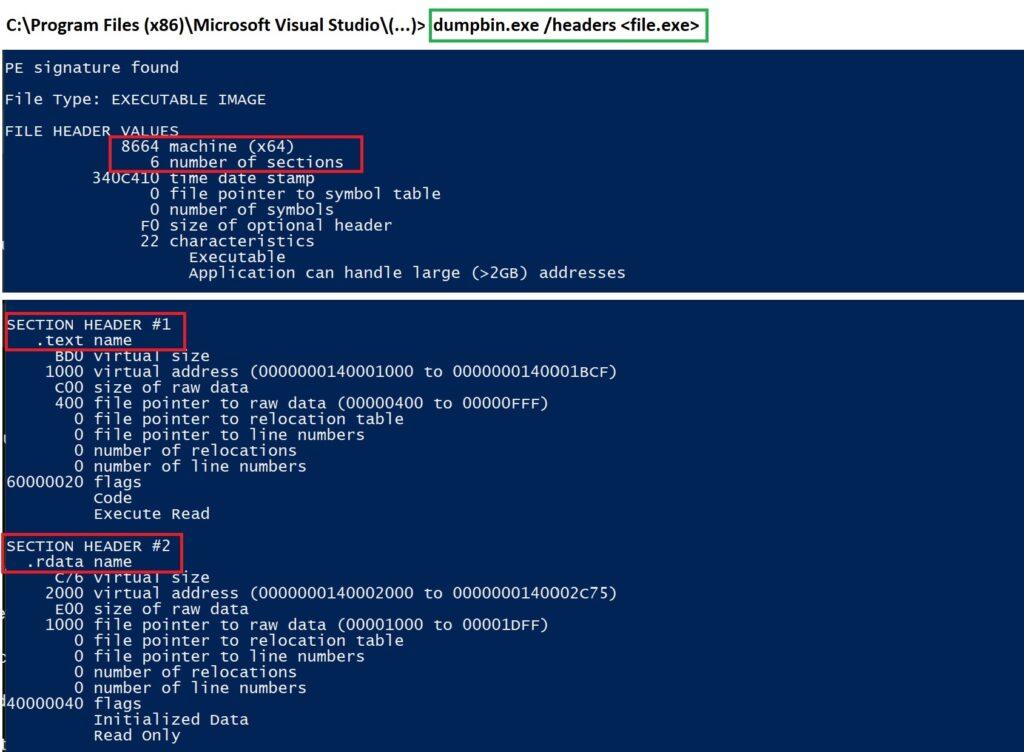
Existen diferentes herramientas que permiten obtener información sobre las cabeceras y las secciones. Por ejemplo, en el paquete MSVC que se utiliza para compilar programas en lenguaje de programación C/C++ de Visual Studio, se incluye la herramienta dumpbin. Esta herramienta se utiliza para mostrar información detallada sobre archivos ejecutables y sus diferentes regiones. Por ejemplo, con el parámetro /headers delante, se obtiene información de estas:
dumpbin /headers <file.exe>
Nota: El paquete MSVC para C/C++ se puede obtener en Visual Studio (2019) como se muestra en la siguiente pantalla. Una vez descargado, las herramientas que proporciona (como dumpbin) se encuentran por lo general en un directorio similar a este, dependiendo de la versión instalada:
C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\SDK\ScopeCppSDK\vc15\VC\bin
Se recomienda crear una variable de entorno en Windows para poder acceder al ejecutable de dumpbin de forma directa desde la CMD o Powershell. Existen diferentes manuales en Internet fáciles de seguir, por ejemplo: https://www.genbeta.com/desarrollo/variables-entorno-que-sirven-como-podemos-editarlas-windows-linux
5.1.2.3. Fases en la creación de un fichero ejecutable
Este bloque se enfocará en las etapas para generar un fichero en formato ejecutable PE para Windows. Se empleará el lenguaje de programación de alto nivel C++ y las herramientas MinGW para compilar y crear un programa. Estas herramientas se encuentran disponibles en diferentes Sistemas Operativos (Linux, macOS), permitiendo crear este tipo de ficheros en entornos diferentes a Windows. Es importante tener en cuenta que este no es el único método para desarrollar un programa.
Existen otros enfoques, como el utilizado por Java, que emplea su propio formato de archivo binario (bytecode) que se ejecuta en un entorno virtual (Java Virtual Machine). En lenguajes como Python, las instrucciones del código fuente se ejecutan directamente a través de un intérprete. Esta variedad de enfoques para desarrollar programas dificulta el análisis de ingeniería inversa de software de manera uniforme. Por tanto, es recomendable concentrarse en un método específico para introducirse en los fundamentos de esta disciplina y después especializarse.
Al proceso para crear una aplicación o fichero ejecutable interpretable por la CPU se le llama de forma genérica compilar o montar. Para compilar un programa, se necesita un software especial y un código fuente escrito en un lenguaje de programación de alto nivel como C++. Este código describe las operaciones de un programa a través de variables, operadores de control de flujo, funciones, etc. Durante este proceso, también se puede obtener otro formato de código especial denominado código objeto o código ensamblador que se analizará en el siguiente punto de esta página (ficheros con extensión .o). Además, durante el proceso de compilación, se pueden incluir referencias a librerías de funciones externas o bibliotecas de enlace dinámico en SO Windows (DLL).
El siguiente esquema muestra el proceso.
Pasando a un ejemplo sencillo, se escribe un programa para sumar en un fichero con extensión .cpp, que contiene el código en lenguaje de alto nivel para C++:
#include <iostream>
// Declaración de función externa que realiza la suma
extern int sumar(int a, int b);
int main() {
int num1, num2;
// Solicitar al usuario que ingrese los dos números
std::cout << "Valor 1: "; std::cin >> num1;
std::cout << "Valor 2: "; std::cin >> num2;
// Llamar a la función sumar e imprimir el resultado
int resultado = sumar(num1, num2);
std::cout << "Suma es: " << resultado << std::endl; return 0;
}
// Definición de la función externa
int sumar(int a, int b) {
return a + b;
}
En este ejemplo, se obtendrá el formato de fichero intermedio que contiene el código objeto, y después el ejecutable (es decir, en dos fases). Para ello se emplea el software de compilación MINGW (este puede descargarse e instalar desde varios sitios, por ejemplo: https://sourceforge.net/projects/mingw/files/ ). En este punto es muy importante señalar que MINGW está especializado para generar ejecutables para el entorno Windows, y permite especificar para que arquitectura de computadora (32 o 64 bits) se va a generar. Conviene destacar también que este mismo código podría emplearse por ejemplo para generar un ejecutable de tipo ELF para Linux, sin embargo, debería utilizarse otro software de compilación.
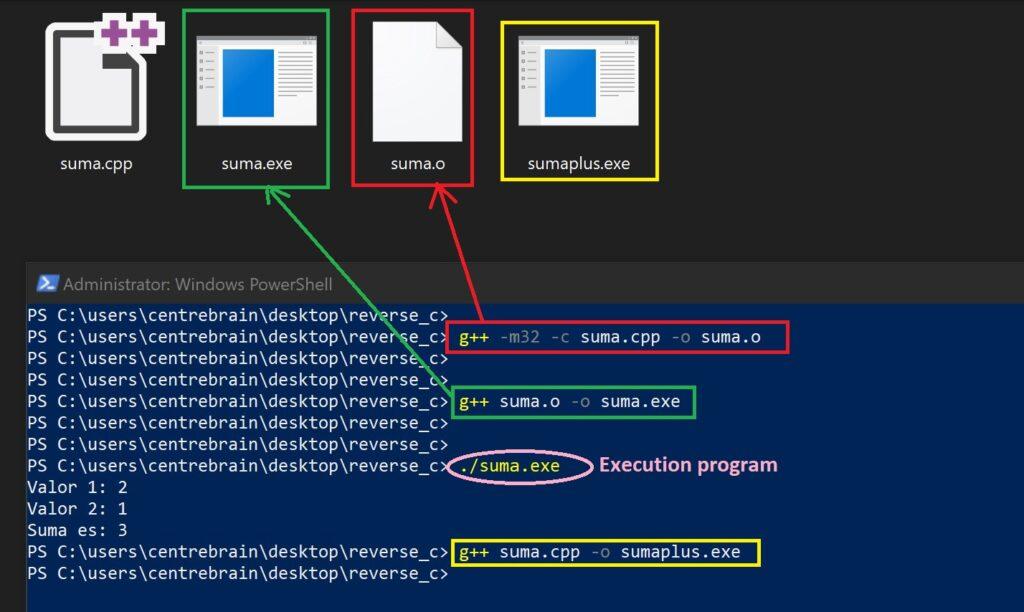
Una vez instalado el paquete de MINGW, se realizarían los siguientes pasos para obtener el fichero de código objeto (ensamblador) y el binario:
1. Compilación: Obtener el fichero de código objeto (extensión .o). En este proceso se indica con el parámetro –mXX para que arquitectura se va a generar:
g++ [-m32 | m64] -c program.cpp -o program.o
2. Compilación/Montaje: Obtención del fichero ejecutable. En esta fase, se asignan las referencias a bibliotecas de enlace dinámico:
g++ program.o -o program.exe
En la siguiente imagen, se muestra el resultado a partir del ejemplo con el fichero original suma.cpp:
Nota: También se puede compilar directamente desde un fichero con lenguaje de alto nivel, sin tener que obtener necesariamente el fichero objeto.
g++ program.c -o program.exe
5.1.2.4. Lenguaje objeto o ensamblador
En el punto Modos de operación de la CPU: instrucciones, registros e interrupciones del bloque de Sistemas Operativos ya se han introducido algunos de los conceptos relacionados con el lenguaje ensamblador. A partir del fichero objeto o directamente desde el ejecutable se puede obtener este código. Como se define en la Wikipedia: “es un lenguaje de programación que se usa en los microprocesadores. Implementa una representación simbólica de los códigos de máquina binarios y otras constantes necesarias para programar una arquitectura de procesador y constituye la representación más directa del código máquina específico para cada arquitectura legible por un programador”. Expresado en otros términos, permite analizar las operaciones que el programa realiza respecto a la CPU y la memoria del sistema.
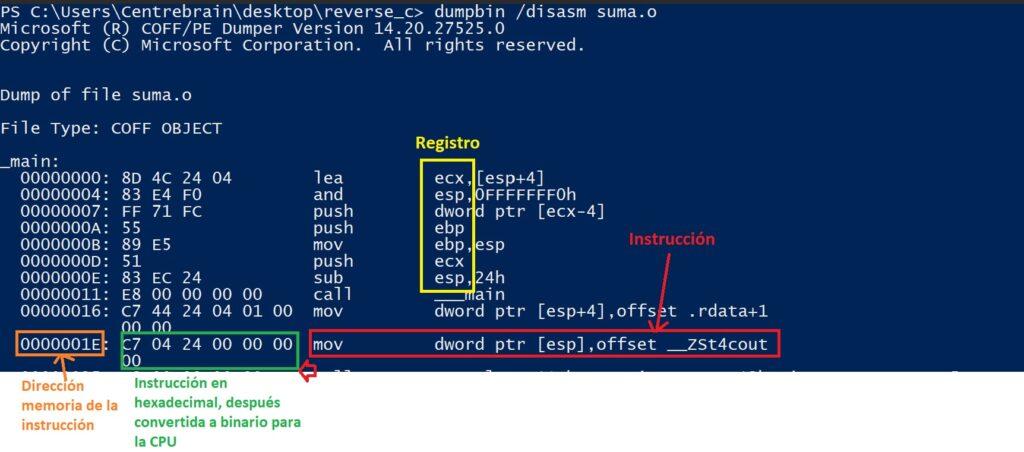
Para acceder a este código a partir del ejecutable o el fichero objeto, se puede hacer con herramientas especiales como un depurador de código ensamblador (ver OllyDbg) o desensambladores. También se puede obtener una impresión con otras herramientas como dumpbin. Por ejemplo, para el programa suma.cpp se realizaría el siguiente comando:
dumpbin /disasm <programa.o | programa.exe>
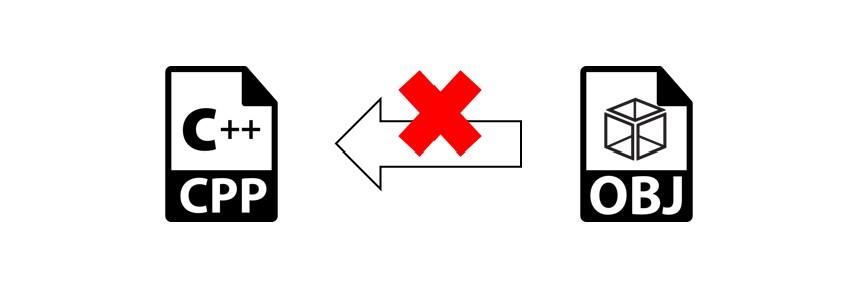
A este lenguaje especial se le denomina de bajo nivel por su dificultad de interpretación. No obstante, es lo más próximo que el ser humano tiene para comprender las funciones de la CPU. Antes de la aparición de los lenguajes de programación de alto nivel, era la única forma de crear programas en el mejor de los casos. Para destacar la importancia de la obtención de este código y realizar operaciones de ingeniería inversa con diferentes fines, se va a repasar algunas nociones sobre este. La operación inversa para obtener el código fuente a partir del código ensamblador de forma directa no es posible. En todo caso, se puede realizar una aproximación sobre el funcionamiento interno del programa a partir de la interpretación del código objeto.
El código ensamblador está formado por instrucciones. Cada línea de código es una instrucción que realiza una operación específica como pasar datos a la pila, comparar valores, registrar direcciones de memoria, etc. Las instrucciones están compuestas por entre 1 y 3 elementos denominados mnemónico y/o operando (separados por espacio o coma). Los mnemónicos y operandos tienen su representación en hexadecimal, de modo que las instrucciones puedan ser interpretables en vez de escribirlas en este sistema numérico: C7 44 24 00 00… (ver imagen superior). Dentro de las instrucciones también se encuentran como operandos los registros (p. ej.: ecx, esp, ebp…) que variarán en función de la arquitectura del procesador para el que se vaya a compilar el programa. El modo de definir las instrucciones viene determinado por la marca del procesador (Intel, AMD, ARM…), su arquitectura (32/64 bits) y el tipo de ejecutable. Por lo tanto, mientras que el código fuente de una aplicación puede ser siempre el mismo, al compilarlo, el resultado en cuanto al código ensamblador puede diferir substancialmente dependiendo del sistema operativo, CPU y arquitectura.
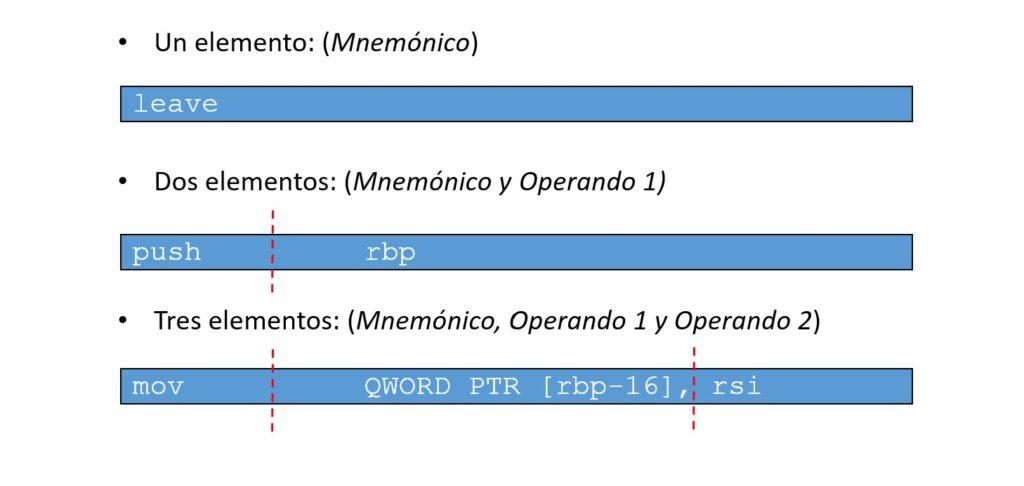
La obtención del código ensamblador de un programa puede ser la primera etapa en el proceso de ingeniería inversa con el fin de obtener vulnerabilidades o realizar determinadas acciones como añadir código de software malicioso, com se verá en los siguientes puntos. Las particularidades del lenguaje ensamblador para las diferentes arquitecturas de CPU, conlleva una serie de puntos paradójicos que conviene destacar:
- Aunque el código de programación fuente de alto nivel sea perfecto en cuanto a seguridad, al realizar el proceso de compilación pueden aparecer vulnerabilidades no controladas por el programador.
- Debido al punto anterior, al compilar el programa para distintos sistemas o arquitecturas, podría presentar vulnerabilidades en una de ellos que no se manifiesten en otras. De ahí la importancia de analizar la estructura de las operaciones resultantes en código ensamblador cuando el programa se compila para diferentes entornos.
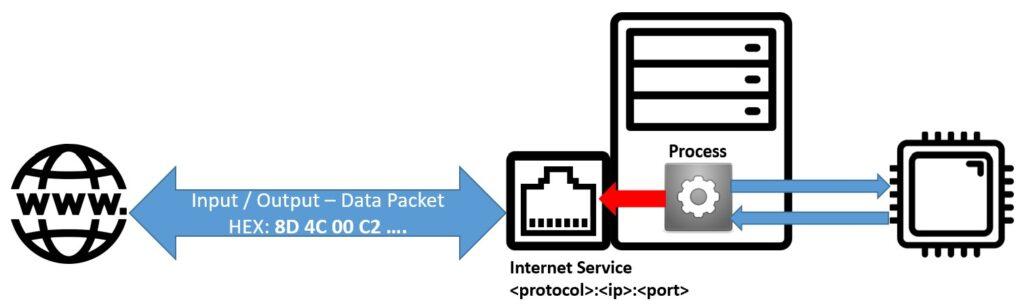
5.1.3. Debugging: Software de red
El debugging es una técnica fundamental para realizar operaciones de ingeniería inversa. Esta técnica consiste en analizar de forma minuciosa el flujo de ejecución del programa a partir un software depurador de código ensamblador como OllyDBG (se verá en el siguiente punto). Estos programas permiten añadir puntos de interrupción en el código para detener la ejecución en puntos específicos, examinar el estado de las variables, el uso de registros de actividad y la revisión minuciosa del código en busca de errores de lógica o sintaxis a partir del código ensamblador. Con la práctica del debugging, en los siguientes puntos se mostrarán algunas de las siguientes técnicas de ingeniería inversa:
- Cracking: Es el proceso de modificar el software para obtener acceso no autorizado o eludir medidas de seguridad.
- Fuzzing: Es una técnica de pruebas de software que consiste en enviar datos aleatorios al programa para encontrar vulnerabilidades o errores y desarrollar exploits.
- Fully Undetectable (FUD) malware: Se refiere a malware que es capaz de eludir la detección por parte de los programas antivirus o soluciones de seguridad. Para su creación, se requiere métodos de debugging avanzado.
Algunas de estas técnicas como el fuzzing, se realizan sobre software de red de tipo servidor como podría ser una aplicación web, un acceso SSH o cualquier otro tipo de servicio en red. Este tipo de software no difiere del software estándar que no requiere el uso de una red informática como podría ser una calculadora o un programa de contabilidad. Al igual que otros programas, un servicio de red se inicia a partir de un fichero ejecutable que genera una serie de procesos que interactúan con la memoria y la CPU de la máquina. La única diferencia sustancial es que los inputs serán los paquetes de datos que circulan en la red, que en última instancia también están formados por código binario cuando son procesados. El análisis de vulnerabilidades en software de red es altamente valorado en ámbitos como el espionaje, el cibercrimen o el desarrollo de software, donde se busca parchar vulnerabilidades para prevenir la introducción de código malicioso (payload) en servidores.