4.4.4. Sistemas operativos: Gestión de la Memoria, sistema de archivos y almacenamiento
Tabla de contenidos:
4.4.4.1. Gestión de memoria
Cuando un programa está en ejecución (i.e. un proceso), sus datos deben residir en la memoria principal (RAM, de la siglas en inglés Random Access Memory) de la computadora. Las operaciones que realiza el Sistema Operativo también deben residir en la memoria principal y por ello se habla de co-residencia. Un componente fundamental de un SO es el administrador de memoria. Este componente asigna memoria principal a los procesos existentes. En este punto se van a introducir una serie de nociones básicas sobre el funcionamiento de la memoria, siempre en un nivel de abstracción respecto a la capa física.
La memoria principal debe entenderse como una serie de bites puestos en línea, con una determinada capacidad para procesar datos (en los ordenadores domésticos actuales puede llegar hasta los 16 o 32 gigabytes de memoria, lo que supone una capacidad considerable). Esta capacidad puede parecer poca respecto a la capacidad de almacenamiento de los formatos de disco magnético (disco duro), que alcanzan capacidades de almacenamiento del orden de centenares de gigabytes. No obstante, incluso en una computadora en la que se ejecuten varios procesos a la vez (multiprogramación), el SO debe saber hacer un uso eficiente de la memoria disponible en función del tamaño de los datos en ejecución de un proceso.
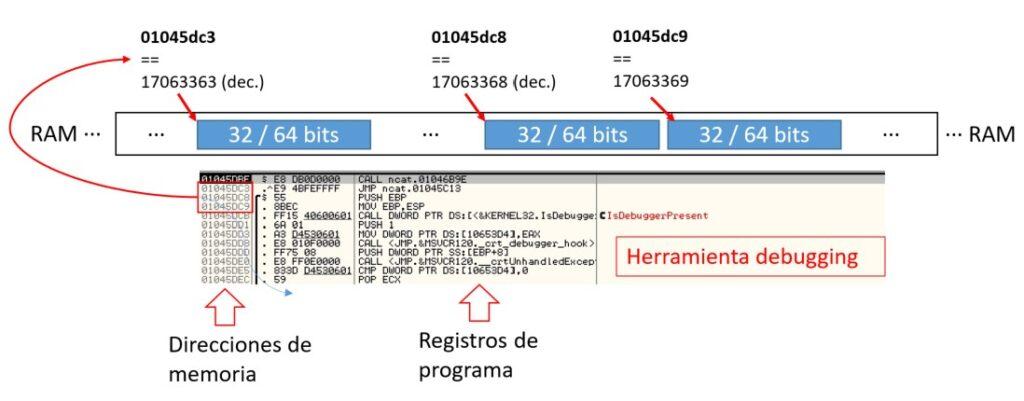
Es habitual que en los programas de debugging para hacer ingeniería inversa de software o depurar código la representación de la memoria se haga en términos abstractos y no mediante notación binaria. Por ejemplo usando un mapa de direcciones de memoria en función de la arquitectura del procesador (32 o 64 bits). Es usual que las anotaciones en este mapa de direcciones se hagan en sistema hexadecimal. Más adelante se ahondará en lo que representan la memoria física respecto a las memorias lógica o virtual, que resultan útiles en función de los tipos de administración de memoria.
Como es de suponer el tamaño en bites que ocupan los diferentes procesos en la memoria es diferente y además se puede ejecutar en diferentes momentos del tiempo, cargando y descargándose. Los sistemas de administración modernos deben ser eficientes en todos los aspectos y en un ambiente multiprogramación deben asegurar estas funciones:
- Reubicación: En sistemas con memoria virtual los programas cargados en memoria deben residir en diferentes partes de la misma en diferentes momentos de la ejecución.
- Protección y compartimiento: Hay que asegurar que un proceso no pueda acceder a las direcciones de memoria de otro proceso. No obstante en ocasiones resulta deseable que los procesos puedan compartir determinados datos y acceder a direcciones de memoria ajenas.
- Organización lógica vs organización física: Como ya se ha comentado arriba, la organización física de la memoria que es una secuencia de bites no es apta para los programas. Para ello un programa se estructura en módulos (segmentos). Por otro lado el SO también debe asegurar la transferencia de datos correcta entre la RAM y otros dispositivos de almacenamiento de datos como el disco duro.
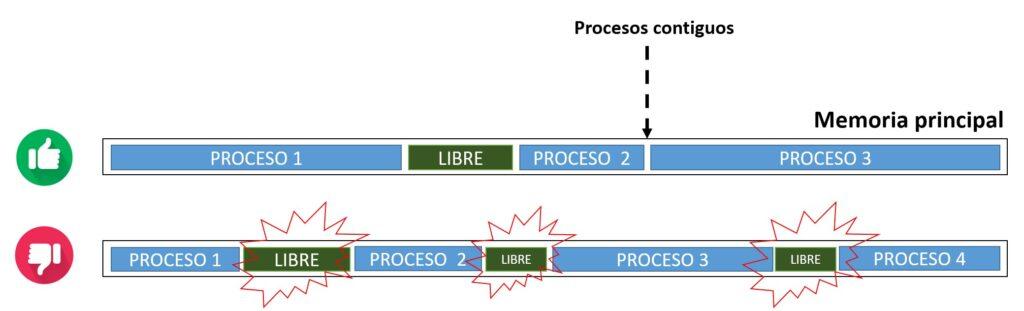
- Compactación: Es deseable tener pocos espacios libres de memoria contigua y no muchos espacios libres y dispersos.
4.4.4.1.1. Modelo o mapa de memoria de un proceso
Desde el punto de vista de la memoria un proceso está muy vinculado al programa ejecutable asociado al mismo. Como ya se ha comentado en puntos anteriores, un fichero ejecutable es el resultado de compilar un código en lenguaje de programación de alto nivel. El ejecutable contiene el código de máquina que el procesador puede comprender (instrucciones). Además, durante el proceso de compilación se añaden referencias a objetos y módulos proporcionados por el sistema de librerías dinámicas del SO (ficheros DLL o Dynamic-Link Library), que es un conjunto de subrutinas compartidas e invocables durante la ejecución del proceso, con todas las ventajas que esto conlleva (estandarización de rutinas y funciones, disminución de tamaño de un ejecutable, etc.)
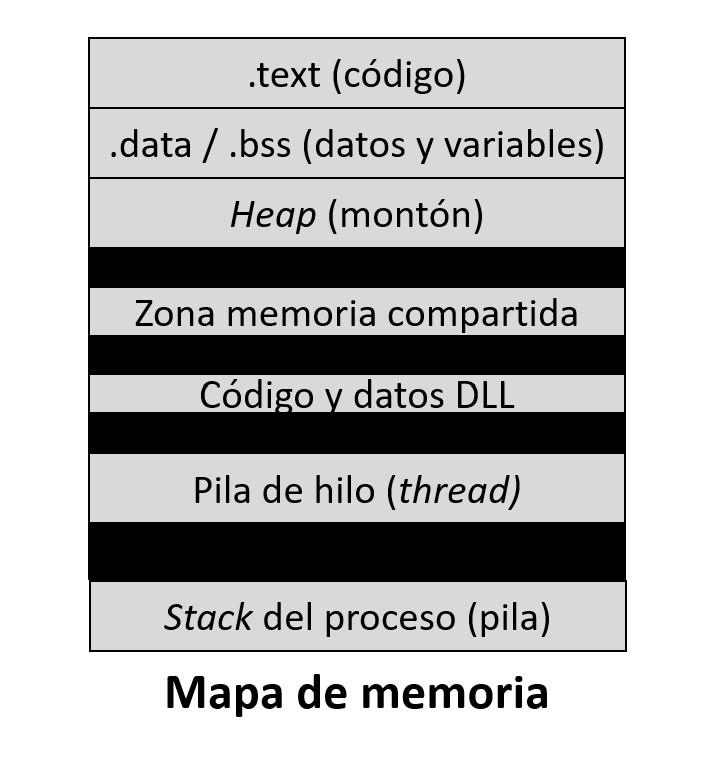
Una vez obtenido el ejecutable (o binario), cuando se activa la ejecución del mismo el administrador de memoria crea un mapa por el cual se crean diferentes secciones a partir de la información contenida en este. Es por ello que el mapa de memoria de un proceso no es algo homogéneo sino que se organiza en regiones o secciones. Cada región es una zona contigua, indicando en el mapa de memoria donde comienza y su tamaño. Además cada una de estas regiones tiene asociadas diferentes características como si tiene uso compartido com otros procesos, si es una región protegida a los diferentes tipos de instrucciones o si es de tamaño fijo o variable, entre otras.
Los diferentes Sistemas Operativos tiene distintos formatos de ejecutables: ELF en Linux (Executable and Linking Format) o PE (Portable Executable) en Windows. A pesar de ello, los diferentes formatos contienen unas cuantas secciones que son comunes. Las secciones principales son:
- Código: Se trata de la sección de memoria que contiene el código del proceso, entendido como la sección de instrucciones. Es una zona de lectura/ejecución y de tamaño fijo. Se la suele llamar .text.
- Variables iniciales y globales: Esta sección incluye las constantes ( ej.: int i = 7) y declaración de variables sin valor definidas en el código del programa (p. ej.: int i[10]). Además, incluye también las variables globales, que se trata de aquellas que son accesibles desde cualquier función definida en el código. Es una sección de tamaño fijo y de carácter no compartido (si un proceso hijo las requiere, se crea una copia). Para este tipo de variables las secciones se denominan .data (las que tienen valor inicial) y .bss (si no tienen valor inicial).
- Pila (Stack): Es una sección de memoria para administrar las variables locales y las invocaciones de funciones. La pila sigue una estructura de datos conocida como LIFO (Last-In, First-Out o último dato en entrar, primero en salir). Cuando se llama a una función, se reservan espacios en la pila para almacenar los parámetros de la función, la dirección de retorno (*) y otras variables locales.
(*) En lenguajes de programación como C y C++, cuando una función es llamada, se guarda la dirección de memoria de la siguiente instrucción después de la llamada a la función, de modo que una vez que la función termine su ejecución, el programa pueda continuar su ejecución desde ese punto.
- Montón (Heap): Se utiliza para asignar y desasignar memoria de forma dinámica. El montón es administrado por el programador y requiere una asignación y liberación explícita de memoria mediante funciones implementadas en los lenguajes de programación de alto nivel como podría ser malloc() en C/C++.
A parte de estas secciones los Sistemas Operativos modernos ofrecen un modelo de memoria dinámico, lo que permite crear o eliminar nuevas regiones durante la ejecución del proceso. Solo a modo de mención, algunas de estas regiones dinámicas que se incorporan al mapa de memoria del proceso pueden ser el de la memoria compartida, pilas para los hilos (threads) o regiones asociadas a la carga de bibliotecas dinámicas (DLL). Evidentemente, no todas las secciones del mapa de memoria son del mismo tamaño y como es de esperar mientras algunas son de tamaño fijo otras pueden variar a lo largo de la ejecución.
En las formas de administración de memoria más primitivos se solía cargar los datos de todo el proceso de forma contigua. En un sistema de computación de monoprogramación en el que solo se ejecuta un proceso esto puede llegar a ser útil (por ejemplo en una consola doméstica). Sin embargo en un ambiente de multiprogramación con una memoria limitada, debido al dinamismo del proceso es probable que no sea necesario cargar determinadas regiones del mapa de memoria hasta que no sean realmente necesarias. La carga extensiva de un proceso podría dejar otros procesos sin espacio en memoria. Afortunadamente, los esquemas de administración de memoria modernos permiten sortear estos problemas (ver siguiente punto a continuación)
4.4.4.1.2. Esquemas de administración de la memoria: segmentación, paginación y memoria virtual
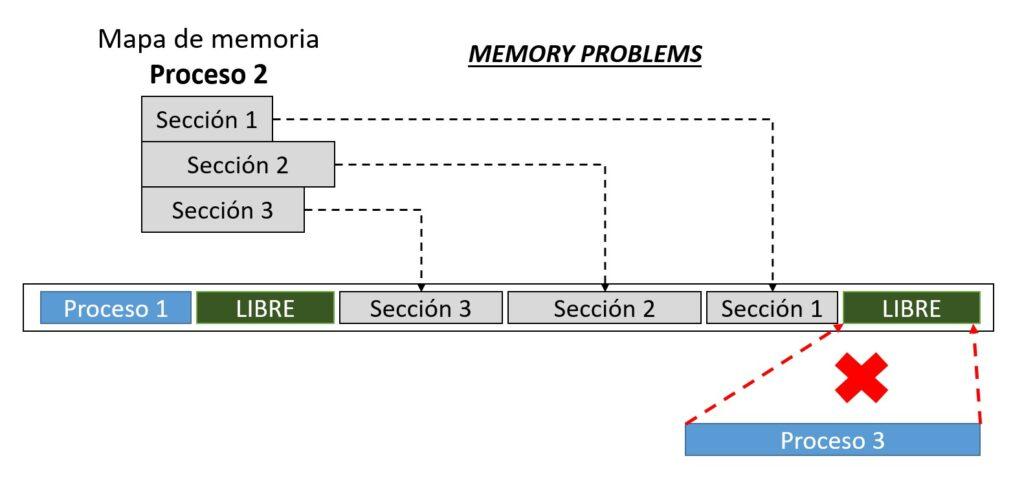
A lo largo de este punto sobre la gestión de memoria, se ha visto que para que esta sea eficiente el SO debe garantizar unos aspectos (compactación, protección respecto a otros procesos, etc.). No obstante, en la operación continua de dividir en bloques la memoria para los procesos entrantes y después volver a liberarla una vez terminado la ejecución del proceso, existe el riesgo de fragmentación. La fragmentación de la memoria se refiere a la división de la memoria en bloques cada vez más pequeños de forma no contigua. Cuando los programas se cargan y se descargan de la memoria, se pueden generar espacios vacíos en la memoria que son demasiado pequeños para alojar programas completos (ver imagen de arriba). Esto puede tener un impacto negativo en el rendimiento general.
Afortunadamente las técnicas y algoritmos de gestión de memoria han ido evolucionando y hoy en día es posible encontrar en los SO la combinación de diferentes esquemas de administración que funcionan bien en los ambientes de multiprogramación. En esta publicación solo se va a dar unos pequeños apuntes para los más usados en la actualidad que combinan los métodos de segmentación, paginación y el uso de memoria virtual. Existen otros esquemas como el método de particiones aunque en la actualidad este se reduce a determinados dispositivos, por lo que no se va a explicar. En todo caso, no es el objetivo de esta publicación dar cuenta de todos los aspectos de estas técnicas. Para más información sobre estos esquemas se puede acudir a la bibliografía sobre Sistemas Operativos.
Reubicación: memorias físicas y lógicas y MMU
Antes de describir algunos de los esquemas de administración de memoria, es preciso saber que en los ambientes de multiprogramación (varios programas ejecutándose a la vez) no es posible saber de antemano que posición en la memoria ocupará un programa cuando se cargue. Esto dependerá de la ocupación de la memoria, además esta posición puede variar en sucesivas ejecuciones. Para ello es necesario realizar un sistema de traducción o reubicación para que las instrucciones y datos de un programa se ajusten a las direcciones de memoria principal asignadas al mismo.
Esto se logra mediante el uso de registros o tablas de traducción que contienen información sobre las direcciones lógicas y físicas correspondientes. La reubicación de direcciones garantiza que el programa se ejecute correctamente sin conflictos de memoria con otros programas en ejecución (cuando se carga un programa en memoria, las direcciones de memoria que utiliza el programa en su código objeto no necesariamente coinciden con las direcciones de memoria física disponibles en ese momento). Es por ello que se distingue entre:
- Direcciones físicas: Son los números en binario que apuntan a posiciones en la memoria física.
- Direcciones lógicas: Son las que utiliza el programa. El hardware de administración de memoria convierte las direcciones lógicas en direcciones físicas. También existen direcciones relativas (o desplazamiento), que son un caso particular y en las cuales las direcciones se expresan como una posición relativa respecto a algún punto conocido.
La reubicación genera un espacio lógico independiente para cada proceso. Esta función la realiza un módulo del procesador llamado MMU, de las siglas en inglés Memory Management Unit. Resumiendo mucho, el programa se carga en memoria desde el ejecutable y durante el desarrollo de su ejecución se traducen las direcciones generadas. El Sistema Operativo guarda para cada proceso que función de traducción de memoria lógica a física le corresponde, indicándole al procesador que función debe utilizar al cambiar de un proceso a otro.
Segmentación con paginación
La segmentación con paginación consiste en aunar las ventajas de dos esquemas de administración de memoria que en su idea original funcionan de forma diferente. Ambos sistemas por separado también gozan de técnicas para proteger la memoria de un proceso de un proceso ajeno, compactación, etc. Descritos por separado de forma muy breve (ampliar en bibliografía):
- Segmentación:
- La segmentación consiste en dividir la memoria lógica en segmentos que se corresponden por lo general a las partes de un ejecutable que se han descrito más arriba: la pila, el código, las variables… Esto implica que cada división o segmento en la memoria puede tener un tamaño diferente, y se asigna a la memoria física según la necesidad.
- La segmentación presenta problemas de fragmentación. No obstante tiene otras ventajas como son organizar y gestionar la memoria de manera más eficiente al permitir compartir segmentos entre diferentes procesos y facilitar el crecimiento y reducción dinámica de los procesos. Exige una gestión compleja por la variabilidad en tamaño de cada bloque, y por eso está en desuso por sí sola.
- Se utiliza una tabla de segmentos para realizar el seguimiento de la ubicación y el tamaño de cada segmento en la memoria. Cada entrada de la tabla de segmentos contiene información sobre el segmento, como su dirección base, tamaño y permisos de acceso. Los segmentos se asignan de manera no contigua.
- Paginación:
- La paginación consiste en dividir la memoria física en porciones del mismo tamaño. Cada una de estas porciones se llama páginas físicas o marcos. Esto facilita mucho la gestión de la memoria física y evita en gran medida la fragmentación. La paginación permite una asignación de memoria flexible y no contigua, ya que los marcos o páginas se asignan a los procesos de manera independiente y pueden ubicarse en cualquier marco de página disponible.
- El mapeo entre páginas lógicas y páginas físicas se mantiene en la tabla de páginas. Cada proceso tiene su tabla de páginas. El mecanismo de direcciones lógica permite aislar entre sí a los programas en ejecución, puesto que no conocen la dirección física efectiva en la que se almacenan los datos a los que se hace referencia.
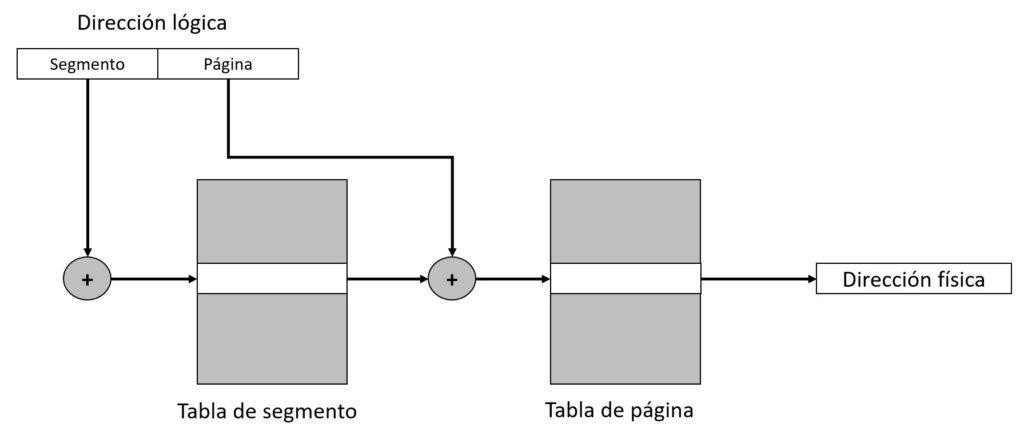
La segmentación con paginación permite combinar lo mejor de cada técnica. Para llevar a cabo este esquema de administración se utilizan direcciones lógicas de memoria segmentada, que son traducidas a direcciones lógicas paginadas (dirección intermedia), que a su vez deben de ser traducidas a direcciones físicas. Por tanto, cualquier acceso a memoria supone un total de tres accesos a memoria. Uno para acceder a la tabla de segmentos, otro para acceder a la tabla de páginas y, por último, otro más para acceder a la dirección física. Cada proceso tiene sus propias tablas de páginas y/o segmentos.
Nota: En este esquema se podían añadir otros elementos como el desplazamiento o el descriptor de la dirección lógica segmentado, pero se han obviado en aras de facilitar la comprensión para todo tipo de usuarios.
Memoria virtual
Las técnicas de gestión de memoria tradicionales solían cargar todas las partes de un programa de manera contigua. Esto resultaba ineficiente pues exige la ocupación de grandes espacios de memoria con secciones del proceso que no se utilizarán de inmediato, o en el peor de los casos que el tamaño total de un proceso sea mayor que el de la memoria disponible (ver gráfico arriba). Derivado de la segmentación, que permite dividir un proceso en varias partes y teniendo en cuenta que las referencias a la memoria de un proceso son direcciones lógicas, el siguiente avance consistió en ver que no era necesario que las partes de un programa se encuentren contiguas durante su ejecución, pudiendo cargarse y descargarse.
Para ello se crea un espacio de direcciones virtuales del proceso. Con ello el sistema operativo guarda aquellas partes del programa en ejecución en la memoria principal mientras que el resto puede permanecer esperando en una unidad de almacenamiento de memoria secundario como podría ser el disco duro (técnica de swapping o espacio de intercambio).
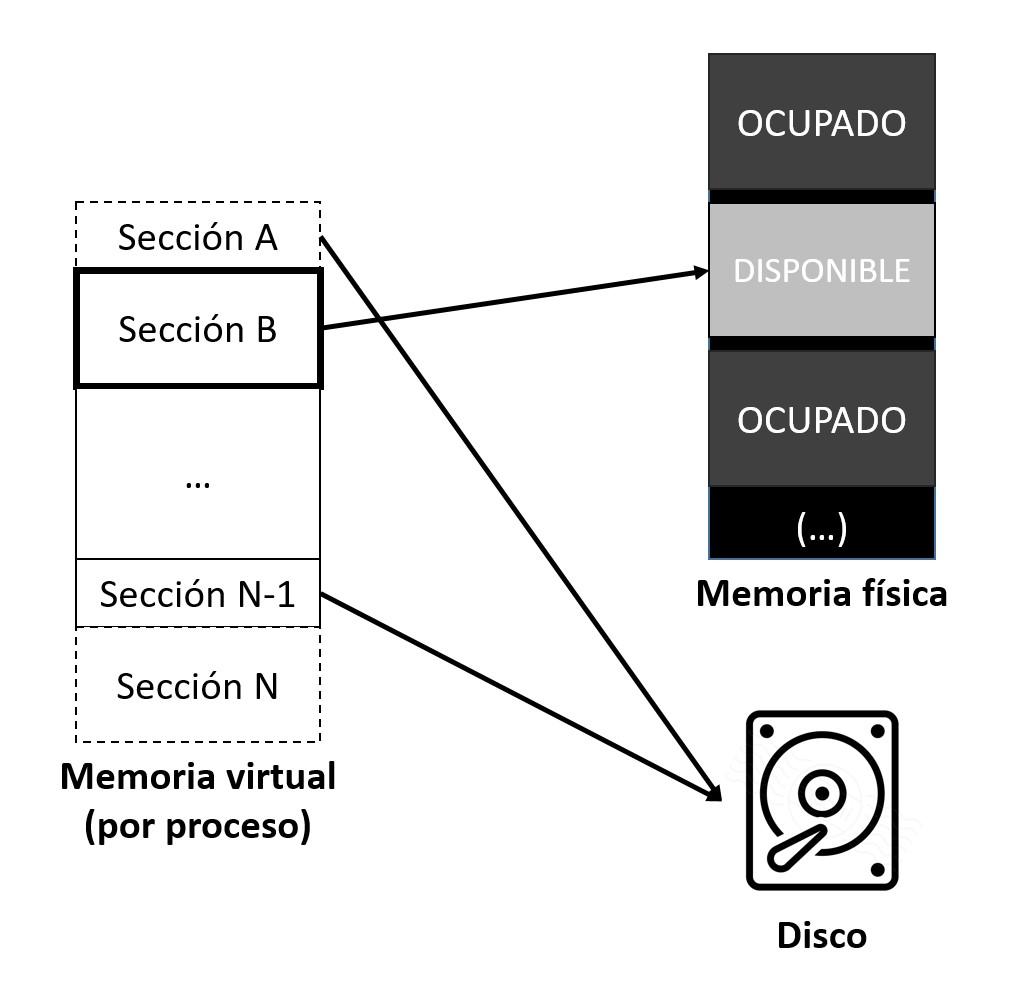
En resumen, en un sistema de memoria virtual el espacio de memoria lógica disponible para un programa es independiente del espacio de memoria física, liberando así a los programas de las limitaciones de la memoria física. En muchos SO se suele combinar un sistema de paginación con memoria virtual. El uso de la memoria virtual puede deshabilitarse en algunos SO, aunque no es recomendable.
4.4.4.1.3. Prácticas de memoria del sistema
Para completar este punto sobre la gestión de memoria se va a ofrecer una serie de comandos y ejercicios en Linux (usando la distribución de Kali Linux).
Memoria virtual: vmstat
La herramienta vmstat ofrece estadísticas del uso de memoria virtual, actividad de la CPU y rendimiento del sistema en general. Puede utilizarse a través de la consola de línea de comandos. Se muestra una tabla con diversos datos. Entre otros, se puede añadir dos parámetros principales: el primero indica el retardo y el segundo el conteo para que muestre información de forma indefinida.
vmstat <delay> <conteo>
En el siguiente ejemplo se ha indicado como parámetros 7 y 12, es decir, que cada 7 segundos muestra una línea de información de rendimiento hasta llegar a 12. Puede observarse como en las líneas centrales se ha producido un cambio significativo en las estadísticas. Esto es porque mientras se ejecutaba la herramienta se han lanzado diferentes aplicaciones como el navegador, etc.
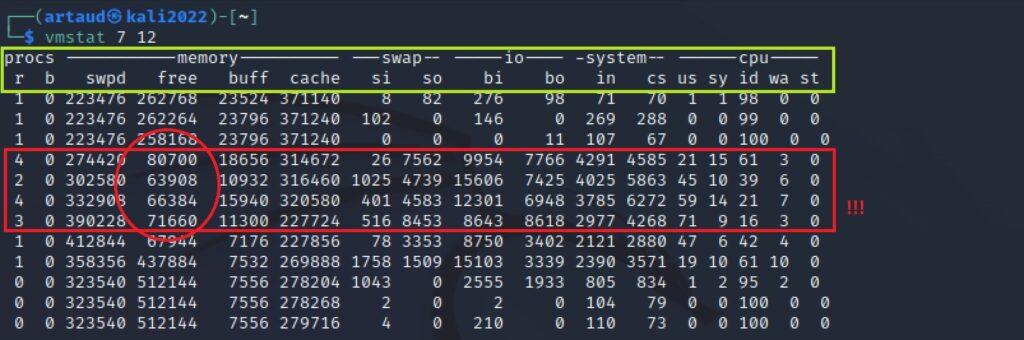
Referente a las columnas que aparecen, esta es la descripción de alguna de ellas:
- procs (procesos):
- r: Número de procesos en ejecución.
- memory (memoria):
- swpd: Memoria swap de intercambio utilizada.
- free: Memoria física disponible.
- swap:
- si: Cantidad de memoria que se está leyendo desde el swap a la memoria principal (técnica swap in).
- so: Cantidad de memoria que se está escribiendo desde la memoria principal al swap (swap out). Los valores no nulos indican que no hay espacio suficiente en la memoria y se están realizando intercambios de memoria entre la memoria principal y el disco.
- system:
- in: Número de interrupciones por segundo, incluyendo interrupciones de hardware y llamadas al sistema.
- cpu:
- us: Porcentaje de tiempo de CPU utilizado para procesamiento de usuario.
- sy: Porcentaje de tiempo de CPU utilizado para procesamiento del sistema.
- id: Porcentaje de tiempo de CPU en estado de ocio (idle).
Para más información: https://docs.oracle.com/cd/E38897_01/html/E23086/spmonitor-22.html
Direcciones de memoria mapa del proceso en Linux
A continuación se ofrece otro ejercicio en lenguaje de programación C. En la sección anterior ya se ha realizado una práctica donde se ha explicado algunas de las líneas de instrucciones comunes así como el procedimiento de compilación. En esta ocasión el programa que se va a obtener permite imprimir las direcciones de memoria correspondientes al proceso que genera el código. El código es el siguiente:
include <stdio.h>
include <stdlib.h>
#Comentario 1
int uig;
int ig = 5;
#Comentario 2
int func()
{
return 0;
}
int main()
{
int local;
#Comentario 3
int *ptr;
ptr = (int *)malloc(sizeof(int));
#Comentario 4
printf("Una direccion del BSS: %p\n", &uig);
printf("Una dirección del segmento de datos: %p\n", &ig);
printf("Una dirección del segmento de código: %p\n", &func);
printf("Una dirección del segmento de pila o stack: %p\n", &local);
printf("Una dirección del montón o heap: %p\n", ptr);
printf("Otra dirección de la pila: %p\n", &ptr);
free(ptr);
return 0;
}
Las referencias a los Comentarios serían:
- Comentario 1: Se declaran dos variables globales, una sin inicializar (uig) y la otra con valor inicial igual a 5 (ig).
- Comentario 2: Se declara una función adicional diferente a main. Esta función devuelve valor 0.
- Comentario 3: En las dos líneas de código siguientes se declara una variable de tipo puntero entero (int) y se le asigna memoria de forma dinámica con la función malloc, usando para ello la noción del montón (heap). Casi al final del código está la función free para liberar la memoria asignada dinámicamente.
- Comentario 4: Se imprimen diferente datos sobre la dirección de memoria en este orden: variables globales uig i ig, función func, variable local, memoria dinámica (ptr) y dirección del puntero.
Un ejemplo de los datos obtenidos al compilar y ejecutar el código serían:

Estadísticas de uso de memoria virtual procesos en Linux
En el anterior punto se ha mostrado el sistema de pseudoficheros procfs en Linux que permite obtener información sobre el estado del sistema. A través de los archivos de procfs (directorio /proc) también se puede obtener información de forma dinámica sobre la memoria virtual que emplean los diferentes procesos. A continuación algunos ejemplos.
El comando cat /proc/swaps muestra información sobre la configuración del espacio de intercambio (swapping). Como ya se ha indicado arriba, la zona de intercambio es un espacio de almacenamiento generalmente ubicado en el disco duro para mover secciones de memoria paginadas de la memoria principal (RAM) cuando se agota la memoria física.
cat /proc/swaps

La información mostrada indica en este orden el nombre de la partición (filename), el tipo de swapping que será partition normalmente aunque también se admite la opción de generar un fichero (file) para hacer la función de intercambio, el tamaño total de la zona en kilobytes (size), el uso (used) y finalmente el valor prority que es un parámetro que indica el valor de prioridad asignado a la partición.
Dentro del directorio /proc también se puede hallar información para cada uno de los procesos. La información de los procesos se obtiene de acuerdo a su PID, siendo el directorio de información general del proceso /proc/<pid>.
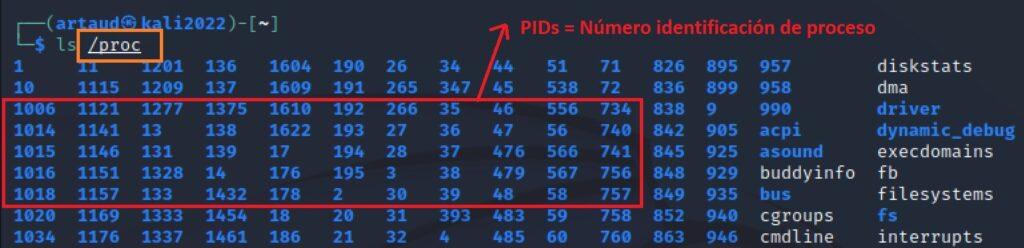
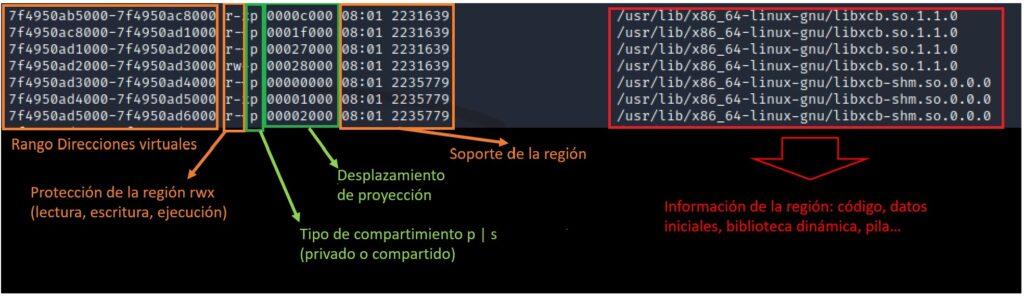
Para obtener la información del mapa de memoria de un proceso se puede ejecutar la siguiente instrucción (para obtener la descripción del proceso se recomienda usar previamente la instrucción ps aux para así obtener el pid). Una muestra de la información obtenida con anotaciones sobre su significado es la siguiente:
cat /proc/<pid>/maps
4.4.4.2. Sistema de archivos y almacenamiento
El sistema de archivos (file system) y la gestión del almacenamiento son otras funciones fundamentales que han de ofrecer los Sistemas Operativos. En las operaciones de informática forense resulta primordial conocer bien estas funciones para preservar la información de los medios de almacenamiento así como obtener evidencias a partir de datos almacenados dentro de un proceso de examen forense digital. No obstante en esta sección destinada a conocer los SO con el fin de explotar un sistema se darán algunas nociones y algún ejemplo práctico, aunque bastante limitado.
La relación entre el sistema de archivos y los sistemas de almacenamiento resulta obvia. El sistema de archivos se encarga de organizar y estructurar la información en los dispositivos de E/S de almacenamiento como podría ser discos duros, lápices de memoria, lectores de dispositivos de disco (DVD, Blue-ray), etc. El sistema de archivos suele ser la parte más visible para los usuarios ya sea a través de un entorno gráfico o bien la consola de línea de comandos. Para facilitar la interacción entre la parte lógica y el software, el sistema de archivos implementa un sistema de archivos virtual, que permite acceder a diferentes tipos de sistema de almacenamiento de forma transparente para los usuarios.
4.4.4.2.1. Conceptos: archivos, particiones y directorios
Archivos y bloques
Los archivos son la parte más visible para un usuario en lo que se refiere al sistema de archivos. Desde la perspectiva del usuario, el archivo permite almacenar y editar información de diferentes tipos, ejecutar aplicaciones o intrucciones, etc. También hay archivos que sirven de soporte a las aplicaciones (bibliotecas de enlace dinámica DLL, etc.). En todo caso, un archivo es conjunto de información relacionada y almacenada en la computadora.
Para el Sistema Operativo el fichero es tratado como una serie de bytes. No obstante, el SO se abstrae del medio de almacenamiento y se maneja en una estructura lógica con la capa de software que ofrece el sistema de archivos de modo que la información organizada en archivos sea inteligible para el usuario. El SO considera un archivo como una colección de bloques lógicos de tamaño fijo. Un bloque es la unidad básica de una operación de entrada y salida entre el disco duro y los buffers de memoria del sistema de archivos. El disco duro en sí mismo es una colección de bloques físicos. Cada bloque físico almacena un bloque lógico y posiblemente algunos datos administrativos.
Otro aspecto importante para el SO en la gestión de ficheros es conocer el tipo de fichero. Para los principales sistema operativos se tiene diferentes modos para identificar:
- Windows: Sistema de ficheros. Permite declarar el tipo de archivo en el nombre de este (ver sección de Introducción).
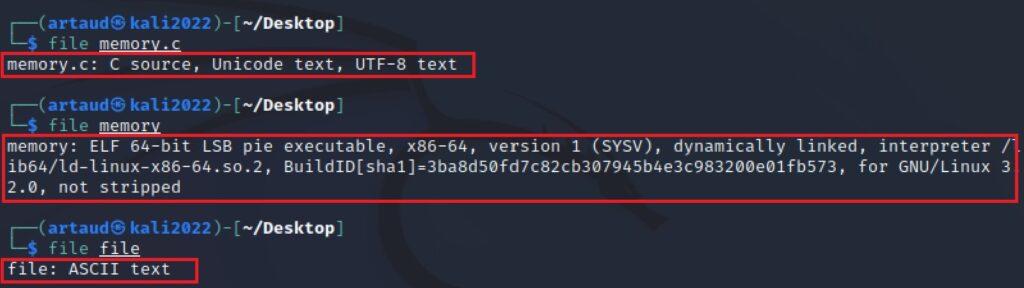
- Linux: Número mágico que se encuentra al principio del fichero. Se puede emplear el comando file en la consola de línea de comandos junto al nombre del fichero para ver el tipo.
Los ficheros también tienen diferentes atributos-metadatos como son el nombre, tipo, tamaño, localización en la memoria, permisos de acceso, identificador del creador, que aplicación lo utiliza, etc. Los SO dan soporte a estos atributos de maneras distintas, siendo estas una forma de crear un mapa para acceder a la información del fichero (estructuras de datos). En Linux se utiliza el sistema de nodo-i o index node, mientras que Windows utiliza el sistema de Master File Tablet.
Almacenamiento en discos duros: particiones y volúmenes
El disco duro de la computadora es por antonomasia el medio de almacenamiento más común. No obstante, un disco duro no es usable por un SO hasta que no se asigna al menos una partición o áreas separadas. Sobre estas particiones el SO define posteriormente un sistema de archivos. Las particiones son útiles para separar los archivos del SO de los que crean y gestionan los usuarios o para crear un área específica para el intercambio de páginas de la memoria virtual. Incluso es posible tener varios sistemas operativos en diferentes particiones y escoger en el momento de iniciar el sistema. En resumen, las particiones son colecciones de sectores contiguos en un disco. Una tabla de particiones almacena el sector de comienzo de una partición, su tamaño, características y se ubica donde la partición.
Otro concepto interesante es del volumen. Un volumen se refiere a una entidad lógica y contigua en un medio de almacenamiento, como un disco duro, una unidad de estado sólido (SSD) o una partición de almacenamiento. Un volumen representa una porción del espacio de almacenamiento físico que se ha asignado y se gestiona como una entidad independiente. Puede contener uno o varios sistemas de archivos, y se utiliza para organizar y administrar de manera eficiente los datos en un medio de almacenamiento. Una partición podría considerarse un volumen, aunque también existen otros tipos de volúmenes como los sistemas de almacenamiento RAID-LUN (Redundant Array of Independent Disks – Logical Unit Number) que resumiendo mucho agrupan varios discos físicos en un solo volumen, los volúmenes para máquinas virtuales o los volúmenes de sistemas de almacenamiento en red.
En resumen, la diferencia principal entre una partición y un volumen es que una partición es una división física y contigua del espacio de almacenamiento en un disco duro o medio similar, mientras que un volumen es una entidad lógica y contigua en un medio de almacenamiento que puede ser una partición o cualquier otra unidad lógica creada y gestionada a nivel de software.
Todos los Sistemas Operativos tienen aplicaciones para obtener información y gestionar los volúmenes y particiones. Por ejemplo en Windows está la Gestión de Discos (Disk Management), pudiendo acceder con la aplicación Run introduciendo diskmgmnt.msc:
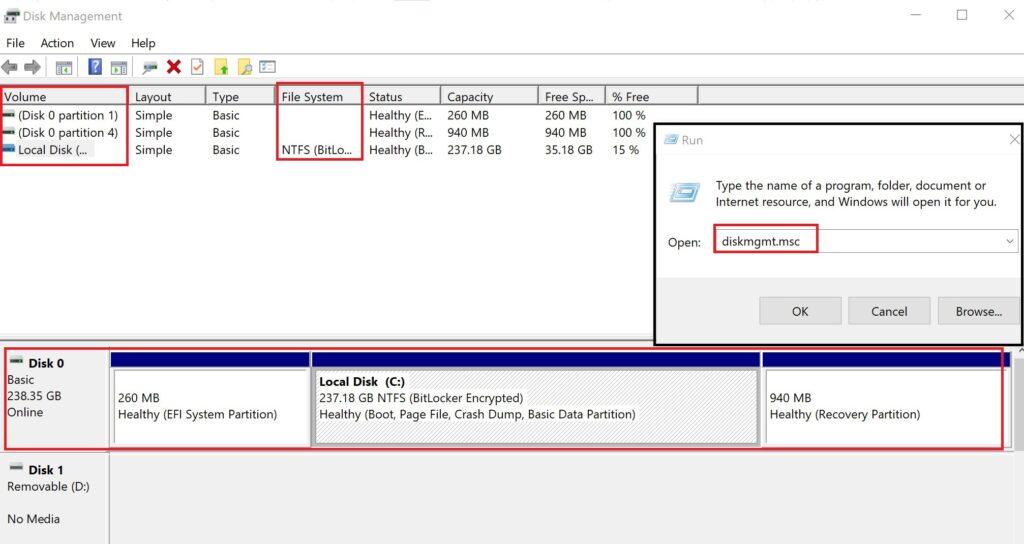
4.4.4.2.2. Sistema de archivos y directorios: Implementaciones y arquitectura en Sistemas Operativos
Una función importante del sistema de archivos es implementar una estructura lógica para la organización de archivos y el mantenimiento de la ubicación física de los archivos. Un objeto imprescindible para mantener esta coherencia es el directorio o carpeta. Este objeto es fácilmente reconocido por cualquier usuario (básico) pues permite ordenar sus archivos. Además de esta función básica para cualquier usuario, un directorio también tiene otra serie de características en el sistema de ficheros:
- El directorio permite relacionar el nombre de un archivo y el descriptor interno del mismo usado por el SO. Un directorio contiene tantas entradas o registros como archivos son accesibles a través de él y su vez oculta los detalles técnicos a los usuarios. El directorio actúa como un índice o una tabla que mapea estos nombres de archivo a la ubicación física o referencia en el disco donde se almacenan los datos del archivo. Esta referencia puede ser una dirección de bloque de disco, un número de sector o algún otro identificador que permita al SO encontrar y acceder a los datos del archivo.
- La información de los archivos se almacena en una entrada de directorio (dependerá del SO el modo). La entrada contienen datos de la propiedad, ubicación, tamaño, eventos (última modificación, creación…). La entrada de directorio apunta a una estructura de archivo distinta en la que está almacenada la información del archivo. Por ejemplo, en los SO Linux esta estructura es el nodo-i o nodo índice (index node o inode). La entrada de directorio solo contiene el nombre del archivo y su número de nodo-i.
- (Cuestión tratada en la Introducción) El usuario se refiere al archivo por un nombre simbólico para su localización de forma unívoca. En un sistema jerárquico como es el de los directorios, el archivo también puede ser identificado desde el directorio raíz. Se trataría del nombre completo (full pathname). En Linux se identifica el directorio raiz con una barra inclinada (/) al principio de una ruta (full pathname), mientras que en Windows el disco lógico (C:) sirve para establecer la raíz. A parte, en los ambientes multiusuarios en ocasiones también se define un home directory para identificar la raíz.
Windows: C:\Users\<user_name_id>\directorio\subdirectorio\…\archivo
Linux: \home\<user_name_id>\directorio\subdirectorio\…\archivo
4.4.4.2.3. Sistema de archivos: tipos de implementación
Un problema del software del sistema de archivos es crear una estructura de datos que establezcan una correspondencia entre el sistema de archivos lógico (como lo ve el usuario) y los dispositivos de almacenamiento, que es como lo ve el SO. Una de las formas para resolver esto es operar por niveles o capas (se podría establecer una analogía con al encapsulado de la suit de protocolos TCP-IP). Cada nivel del diseño aprovecha las funciones de los niveles inferiores para crear nuevas funciones que se usarán en los niveles superiores. Por ejemplo, en un diseño de 3 capas:
- Control de E/S en el nivel más cercano al hardware. Consta de manejadores de dispositivos (drivers) y manejadores de interrupciones para transferir información entre la memoria y el disco duro. También denominado sistema de archivos básico o nivel de entrada y salida física, solo se necesita emitir órdenes genéricas al driver del dispositivo para leer y escribir bloques físicos en el disco.
- Módulo de organización de archivos: Conoce los archivos y sus bloques lógicos, además de los bloques físicos y puede traducir entre direcciones lógicas y direcciones físicas.
- Sistema de archivos lógico: Emplea la estructura de directorios para proporcionar al módulo de organización de archivos lo que este necesita.
En relación a los procesos que se han visto en este bloque de Sistemas Operativos (y resumiendo mucho), cuando un proceso abre un archivo efectúa una llamada al sistema y es el SO el encargado de abrirlo y gestionar el hardware para que realice las operaciones de E/S. El SO le devuelve un descriptor de archivo (Linux) o manejador de archivo (Windows) al proceso, que es una clave abstracta para acceder al archivo y que el proceso utiliza para en las llamadas subsiguientes para realizar operaciones de lectura, escritura u otras operaciones relacionadas con el archivo.
Las implementaciones de sistemas de archivos más modernos actualmente serían para Windows el NFTS (New Technology File System) y para Linux el Ext4 (Fourth extended filesystem). Para ampliar la información sobre su funcionamiento y otros aspectos más técnicos sobre los sistemas de archivos y la gestión del almacenamiento se pueden consultar la bibliografía mostrada al principio del bloque de Sistemas Operativos.
4.4.4.2.4. Sistema de ficheros y almacenamiento: Casos prácticos
Sistema de ficheros y Shell
En un sistema operativo moderno, existen diferentes soluciones de software que permiten al usuario interactuar con archivos y directorios, ya sea a través de un entorno de escritorio gráfico o de una consola de línea de comandos. A lo largo de este curso se han mostrado varios ejemplos de cómo interactuar con comandos.
La consola de línea de comandos se define como un programa que proporciona una interfaz de texto al usuario para interactuar con el sistema operativo. También se conoce como shell y actúa como un intérprete de comandos en el argot informático. Como se ha visto en diferentes ejemplos, la shell permite ejecutar programas, administrar procesos, configurar variables de entorno, automatizar tareas mediante scripts, entre otras funciones. Además, ofrece comandos relacionados con el sistema de archivos, como ls para listar el contenido de un directorio, cd para cambiar de directorio, mkdir para crear un nuevo directorio, rm para eliminar archivos, entre otros. Estos comandos se comunican con el sistema de archivos subyacente para realizar las operaciones requeridas.
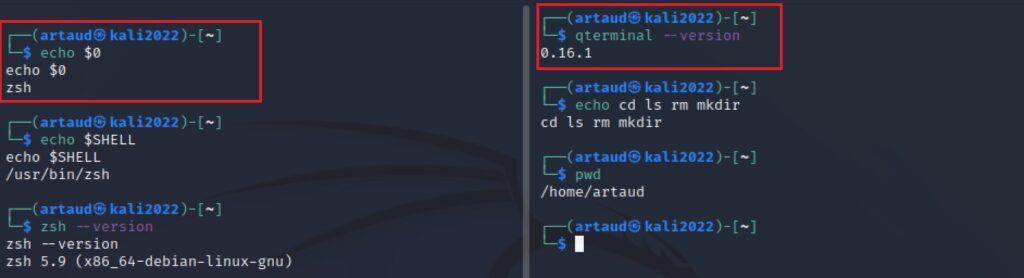
Es importante distinguir la shell de un emulador de terminal. Un emulador de terminal es una aplicación que brinda una interfaz gráfica que simula el comportamiento de una terminal de texto en un entorno gráfico. En Kali Linux, el software de shell utilizado hasta ahora es zsh, mientras que para el emulador de terminal se utiliza qterminal. A continuación, se presentan algunos comandos en la siguiente pantalla para obtener información sobre las características de la shell en uso.
#Drerminar la shell que se está utilizando
echo $0
#Información adicional sobre la shell
echo $SHELL
Almacenamiento: particiones y volúmenes en Linux y Windows
A continuación se van a mostrar algunos ejemplos para obtener información sobre las particiones y volúmenes a través de la consola de línea de comandos de los principales SO. En Linux se tienen el comando mount que se utiliza para montar un sistema de archivos en un directorio específico, lo que permite acceder y utilizar los archivos y directorios contenidos en ese sistema de archivos de forma transparente para el usuario (i.e., independiente del medio físico del almacenamiento).
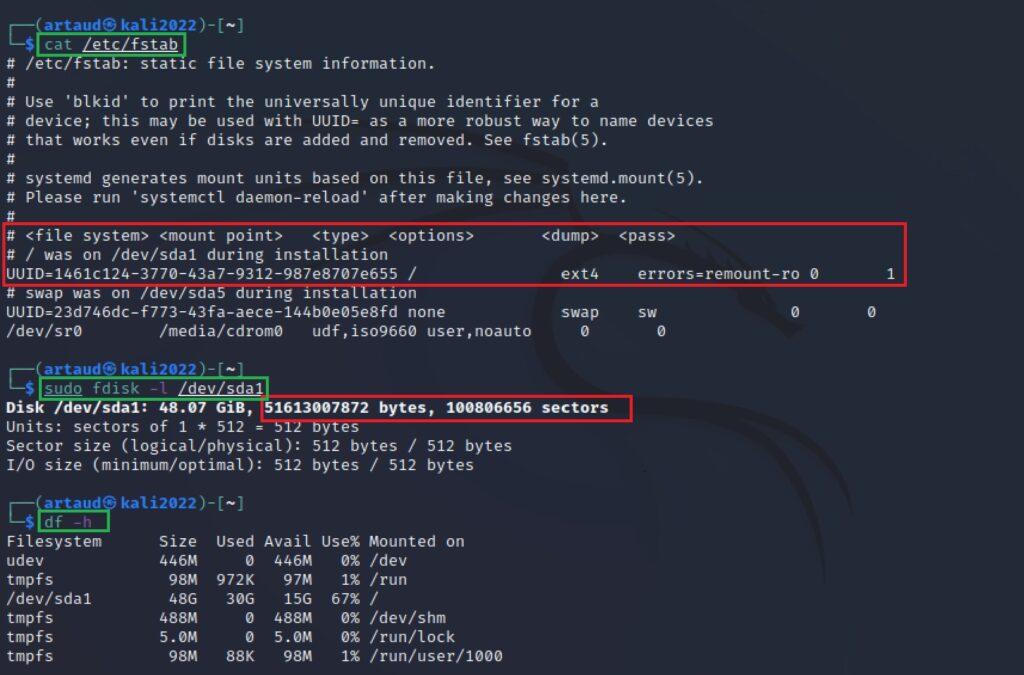
Aunque aquí no se van a mostrar todas estas opciones del comando mount. El empleo de mount solo en la shell permite mostrar volúmenes y particiones montadas en el sistema (primera columna) y el directorio en donde han sido montados (segunda columna). También ofrece entre otra información el tipo de sistema de archivos montados (ext4, NFTS, FAT, etc.). En este ejemplo, la partición principal es /dev/sda1 (con ext4):
mount

El comando mount recoge la información del archivo / etc /fstab, que contiene información de los distintos tipos de particiones y volúmenes del sistema. Con el comando fdisk y el nombre de la partición también se obtiene información sobre la capacidad y sectores (relacionado con los bloques) del disco que se ha comentado en esta sección. Otro comando que resume información es dh. Algunos de estos comandos tienen que ser utilizados con permisos root:
cat / etc /fstab
sudo fdisk -l <particion_volumen>
df -h
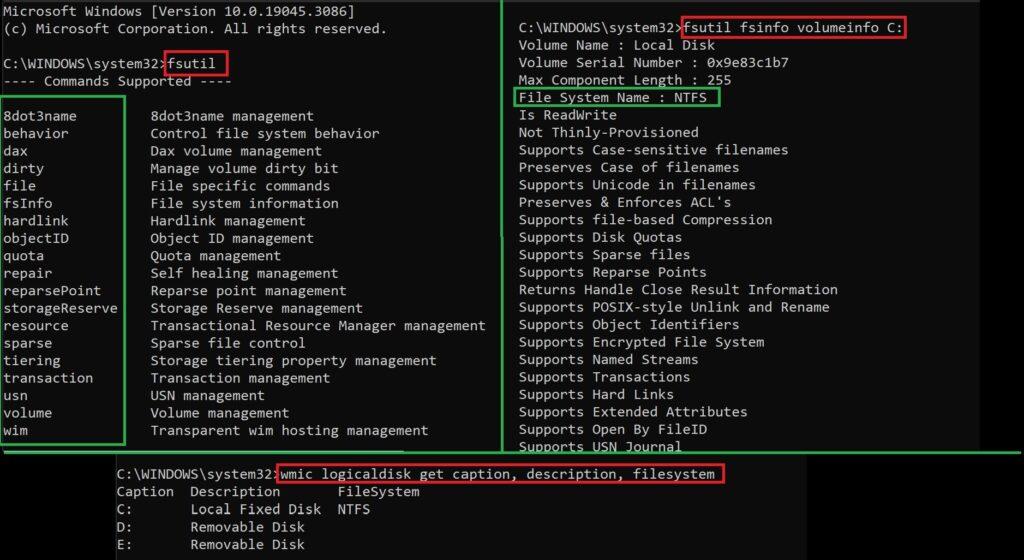
Para Windows ya se ha mostrado anteriormente como obtener información de la distribución de particiones y volúmenes con la aplicación nativa Disk Management. No obstante, también es posible obtener información a través de la CMD (shell en Windows). El comando fsutil proporciona varias utilidades sobre la administración del sistema de archivos, pudiendo obtener información detallada sobre un volumen específico. Otro comando que también permite obtener información similar es wmic (Windows Management Intrumentation Command-line). Estos serían algunos ejemplos: